
Positive Technologies разработала нейросеть MOLOT для обнаружения вредоносного кода в программах на самых популярных в мире языках — Python, JavaScript и TypeScript. Как и большие языковые модели, MOLOT построена на архитектуре «трансформер». Нейросеть уже работает в анализаторе, который ищет уязвимости и слабые места в коде — PT Application Inspector начиная с релиза 6.0.
Чем MOLOT отличается от других
В отличие от классических средств анализа, которые ищут отдельные опасные куски кода по заранее заданным правилам, MOLOT смотрит на программу как на последовательность действий и оценивает, складываются ли они в подозрительный сценарий. Это позволяет находить вредоносный код на 15% точнее классических правил и делает PT Application Inspector вторым в мире SAST-продуктом (инструментом статического анализа кода), способным обнаруживать такие угрозы по поведению программы.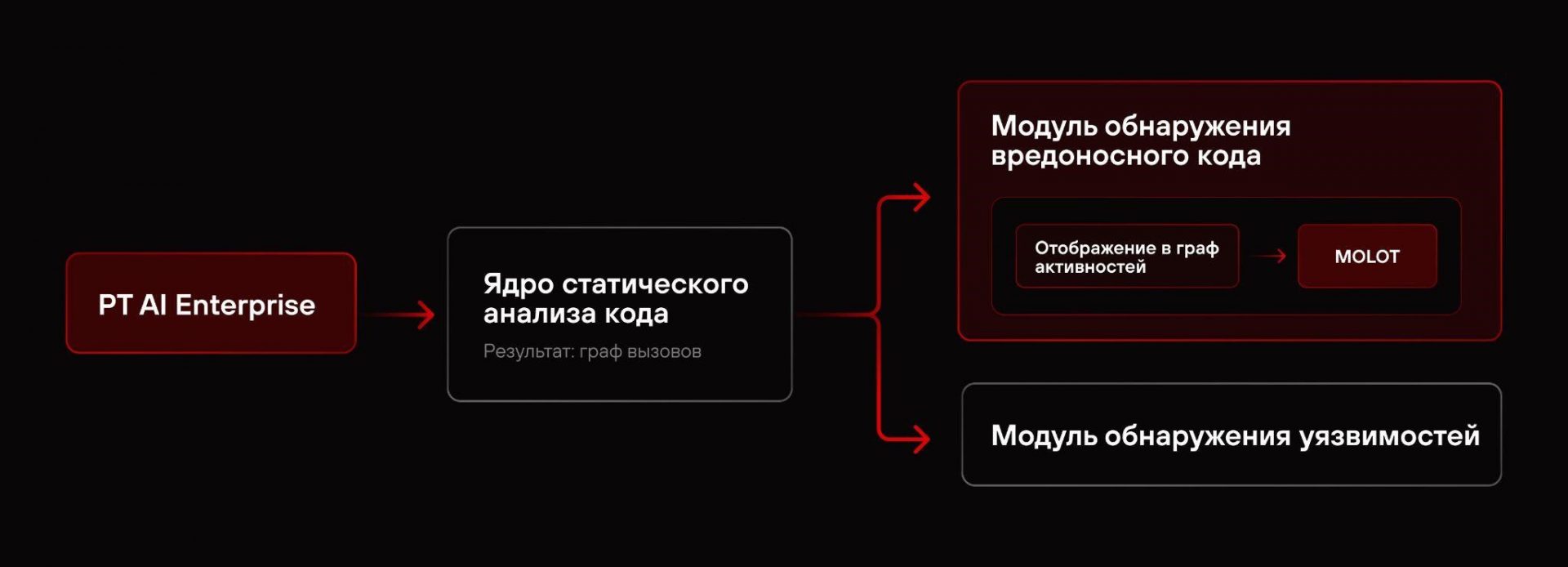
Большинство инструментов анализа кода ищут уязвимости, то есть ошибки и недостатки конфигурации, через которые проект можно атаковать извне. Но недавние инциденты, в том числе кейс LiteLLM, показывают, что намеренное внедрение вредоносного кода в сам проект часто остается незамеченным при проверке безопасности. Такой код не использует уязвимости, он работает с теми же правами, что и обычное приложение, поэтому традиционные средства его не замечают. Этот класс угроз описан в CWE-506.
Сложность в том, что отдельные действия вредоносного кода выглядят безобидно: прочитать файл, отправить запрос в сеть, расшифровать строку, запустить процесс. Все это встречается и в обычных приложениях. Опасным код становится тогда, когда эти действия выстроены в определенную последовательность, например скрипт читает логин и пароль, кодирует их и отправляет на сторонний сервер. Классические правила, проверяющие отдельные конструкции, такие сценарии пропускают.
MOLOT устроена иначе. Из кодовой базы извлекаются все действия, которые программа совершает при работе: обращения к сети, к файлам, запуск процессов, использование криптографии и так далее. Они собираются в последовательность и подаются в нейросеть. Так же как большие языковые модели учатся понимать тексты по последовательности слов, MOLOT учится понимать программы по последовательности их действий и отличать сценарии, характерные для вредоносного кода, от обычных.
Что показало тестирование
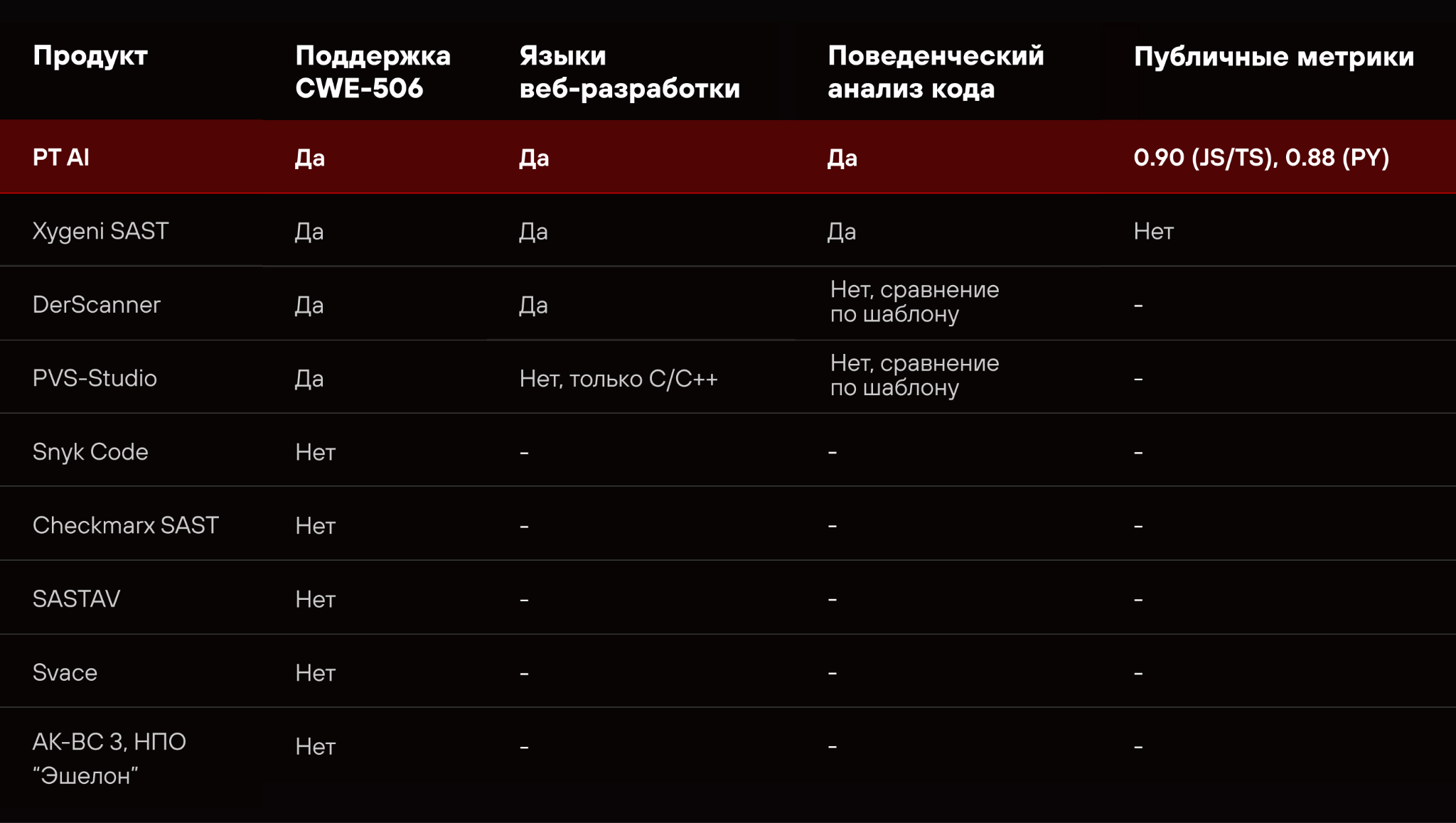
«Тестирование на реальных вредоносных пакетах из репозиториев PyPI и npm показало, что MOLOT находит вредоносный код точнее open-source аналогов, разница доходит до 30 процентных пунктов на части тестов. Чтобы наши результаты можно было независимо перепроверить, мы публикуем сбалансированный набор данных и сценарии запуска как открытый бенчмарк», — рассказал руководитель ML-команды Application Security в Positive Technologies Максим Митрофанов.
Пример работы модели: компания принимает проект от подрядчика или внешнего сотрудника. Репозиторий большой, содержит множество бизнес-логики, в том числе: чтение паролей из переменных окружения, декодирование переменных, использование их для составления сетевого запроса. Каждое из этих действий по отдельности встречается в сотнях легитимных библиотек, и сигнатурные правила его пропускают. MOLOT видит всю цепочку целиком и помечает ее как подозрительную.
Для каждой сработки модель не только выдает вердикт, но и подсвечивает конкретные строки кода, по которым она приняла решение, поэтому аналитик за пару кликов переходит к фрагменту и проверяет вывод.
Источник: Positive Technologies


