Как технология in—memory изменила бизнес-аналитику

Можно долго рассуждать о том, как бизнес-аналитика помогает финансам или логистике. Способов применить информацию много, постоянно появляются новые. Но принцип работы разных аналитических решений один и заключается он в том, чтобы соединить данные из разных источников и посмотреть на них в комплексе. Чтобы воспользоваться информацией из нескольких источников, нужно к ним подключиться и извлечь данные. Но создаются данные разными способами, с разной периодичностью и хранятся в различных форматах. Потому до визуализации или передачи данных другим системам для дальнейшей обработки их приходится объединять с помощью математических операций, т. е. трансформировать. Рассмотрим, как и почему меняются технологии, составляющие основу современных аналитических решений.
Технология in-memory [1] заключается в том, что для трансформации в оперативную память единовременно загружаются все данные из разных источников. После этого трансформацию можно выполнить на лету, без запросов к диску. Например, кликом выбрать измерение и сразу получить график, отображающий значения показателей в необходимом разрезе. Благодаря тому, что все данные находятся в оперативной памяти, аналитическому приложению не нужно делать запросы к жесткому диску для получения новой информации.
Сначала было дорого
«Память – это новый диск», – заявил исследователь из Microsoft Джим Грей (Jim Grey) в начале нулевых. В 2003 г. в своей статье «Экономика распределенных вычислений» [2] он сопоставил стоимость различных этапов компьютерной обработки данных. Джим Грей показал, что вычисления должны быть там же, где находятся данные, – чтобы лишний раз их не перемещать. Он советовал передвинуть вычисления как можно ближе к источникам данных, т. е. отфильтровать данные как можно раньше и в результате сэкономить.
В течение нескольких последующих лет на рынке появились in-memory СУБД сразу от нескольких лидеров индустрии, включая Oracle, IBM, и SAP, а также несколько Open Source-проектов, например Redis и MemcacheDB.
Первыми задачами, которые решали in-memory СУБД, оказались не бизнес-аналитика и даже не бизнес-приложения, а возможности электронной коммерции, открывающиеся в результате мгновенного извлечения информации. Например, in-memory СУБД могла бы позволить интернет-магазину в реальном времени предложить покупателям товары на основе их предпочтений либо показывать рекламу.
Рынок решений для анализа корпоративных данных развивался по другой траектории. Большая часть предприятий неразрывно связана с системами, использующими транзакционные СУБД, которые основаны на принципах, разработанных еще в 80-х гг. прошлого века. Их задача – постоянно сохранять на диск идущие потоком небольшие порции данных и подтверждать их целостность (OLTP-сценарий работы). Среди систем, использующих такие СУБД, – ERP-решения, автоматизированные банковские системы, биллинг, POS-терминалы.
Но аналитические задачи требуют от базы данных совсем другого. Здесь нужно быстро извлекать ранее сохраненную информацию. Причем большими кусками – для каждого аналитического отчета понадобятся абсолютно все данные, которые должны быть в нем отражены. Даже в том случае, если отчет состоит из одной цифры.
Выгружать данные хорошо бы как можно реже, потому что их объем может быть велик, а загрузка большого набора данных с помощью аналитических запросов натолкнется на несколько препятствий.
Во-первых, хранящий информацию жесткий диск – медленный накопитель. Во-вторых, структура хранения данных в традиционной СУБД не позволит ей быстро выполнить аналитический запрос. Данные сохранялись построчно – по мере их поступления, поэтому физически рядом находятся значения, которые относятся к одной строке. В ответ на аналитический запрос базе данных требуется отдать значения одного столбца, но из разных строк. Поэтому такие запросы выполняются медленно, создают большую нагрузку на систему хранения данных. То есть расположение информации на диске организовано неподходящим способом.
Таким образом, традиционные СУБД, в которых изначально сохранялась вся исходная для анализа информация, плохо подходили для того, чтобы выполнять роль источника данных, к которому аналитическая система подключается напрямую. Поэтому в прошлом веке для аналитических задач стандартной практикой было использование промежуточной модели данных, в которой все значения рассчитаны на какой-то момент времени. Такая модель данных называлась «аналитическим кубом», или OLAP-кубом. Для создания OLAP-куба разрабатывались ETL-процессы (extract, transform, load) – запросы к базам данных в исходных системах и правила, в соответствии с которыми нужно преобразовывать данные. Очевидно, если в OLAP-кубе какой-то информации нет, то в отчете она появиться не может.
Проблема такого подхода заключалась в высокой стоимости решения. Во-первых, требовалось хранилище данных, куда будут помещаться предрассчитанные показатели. Во-вторых, если какой-то показатель понадобился в другом разрезе, то для его получения все процессы трансформации данных на пути от исходной системы к OLAP-кубу приходилось создавать заново переписыванием аналитических запросов. Затем нужно было пересчитать весь OLAP-куб, что занимало несколько часов.
Допустим, OLAP-куб содержит информацию о продажах по разным странам. Но финансовый директор захотел увидеть продажи в разрезе городов, а потом сгруппировать их по критерию «средний чек». Для получения такого отчета он был вынужден обращаться в ИТ-службу, чтобы она перестроила OLAP-куб. Либо мог форсировать события и привлечь знатока MS Excel, который создал бы такой отчет вручную. Для этого ему приходилось выгружать с помощью аналитических запросов данные из исходных систем в таблицы и проделывать с ними ряд трудоемких и недекларируемых манипуляций.
В первом случае финансовому директору приходилось ждать, а во втором он получал цифры, которым трудно доверять. Кроме того, решение обходилось дорого. Нужно было инвестировать в создание и администрирование хранилища. Требовалось нанимать специалистов по СУБД, для того чтобы они занимались ETL – перестраивали OLAP-кубы под каждую из задач. Параллельно в компании обычно появлялись специальные аналитики, которые создавали отчеты по запросу (ad-hoc отчеты). Фактически они изобретали разные способы получить нужный отчет с помощью MS Excel и преодолевали трудности, связанные с тем, что программа предназначена для решения других задач.
В результате составление отчетности обходилось дорого даже для крупных компаний. Менеджеры, представляющие малый и средний бизнес, довольствовались возможностями программы MS Excel.
Решение нашлось
В 1994 г. тогда еще шведская компания QlikTech из небольшого города Лунд выпустила программу QuikView, позже переименованную в QlikView. Приложение, разработанное для оптимизации производства, позволяло узнать, использование каких деталей и материалов взаимосвязано, а каких – нет. То есть для визуализации логических связей между частями, материалами, агрегатами и продуктами программа загружала в оперативную память наборы данных из различных источников, сопоставляла их и мгновенно справлялась с заданием. Например, несколько таблиц с указанными в них актерами, их ролями в фильмах, режиссерами, жанрами, датой выхода, сборами – чем угодно – загружаются в оперативную память. Теперь можно кликом по любому параметру выбрать его и сразу увидеть все другие, связанные с ним. Кликаем по Брэду Питту – получаем кассовые сборы всех фильмов, в которых он снимался. Выбираем комедии – получаем сумму кассовых сборов комедий с Брэдом Питтом. И все это мгновенно, в реальном времени.
Хотя в те годы на рынке корпоративных информационных систем аналитические задачи решались с помощью промежуточных моделей данных – OLAP-кубов, подход QlikTech оказался значительно удобнее, поскольку позволял отказаться от промежуточного этапа в виде расчета OLAP-куба и существенно на этом сэкономить.
Аналитическое приложение напрямую подключалось к источникам и периодически загружало все нужные для отчета данные в оперативную память. Исчезла необходимость каждый раз менять ETL-процессы для получения значений показателей в новых разрезах – теперь они подсчитывались в реальном времени в момент запроса. Кроме того, отпала потребность создавать и администрировать хранилище данных. Стоимость владения аналитическим решением резко снизилась.
По мере распространения 64-разрядных серверов, которые давали возможность работать с бóльшим объемом оперативной памяти, технология in-memory стала быстро менять бизнес-аналитику, что хорошо иллюстрируют отчеты Magic Quadrant исследовательской компании Gartner. В 2016 г. квадрант лидеров покинули сразу шесть разработчиков BI-платформ, среди которых такие ветераны отрасли, как IBM, Oracle и SAP. Остались три игрока, сделавших ставку на технологию in-memory и отказавшихся от OLAP-кубов, – Microsoft, Qlik и Tableau.
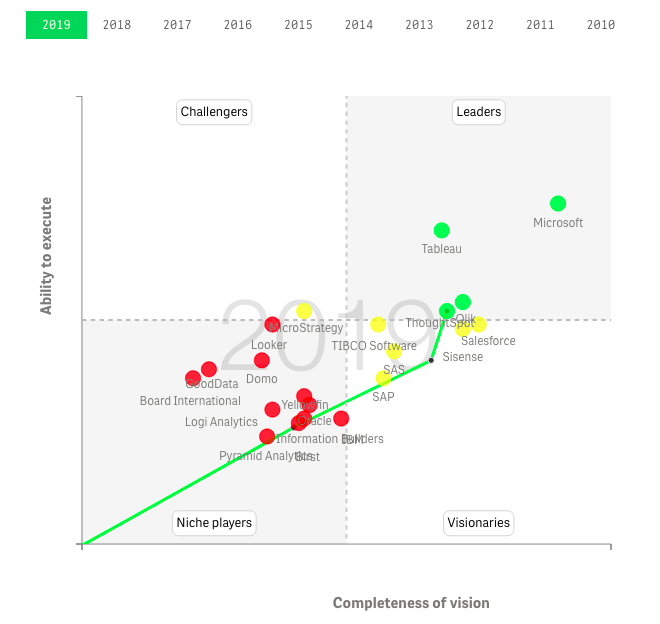
Рисунок. Положение игроков в Gartner’s Magic Quadrant for Analytics and Business Intelligence Platforms’2019. Динамика изменения доступна по ссылке https://qap.bitmetric.nl/extensions/magicquadrant/index.htm (год можно выбрать сверху)
Можно сказать, что компания Qlik стала пионером и лидером трансформации рынка. К 2016 г. платформу для анализа данных QlikView использовали заказчики по всему миру, годовой объем продаж превысил 600 млн долл.
От отчетов к управлению компанией на основе данных
По мере распространения аналитических решений, основанных на технологии in-memory, для огромного количества компаний открылась недоступные раньше способы использования корпоративных данных. Появилась возможность не ограничиваться управленческими отчетами, стандартными для каждой отрасли. Различные процессы стали «измерять» – вводить метрики и использовать их для описания процессов. Стало гораздо проще пользоваться объективной информацией, важной для принятия более обоснованных решений. Резко увеличилось количество бизнес-пользователей, работающих с данными.
Огромное влияние на интерес к применению данных оказали изменения потребительского поведения. Маркетинг стал цифровым – основанным на метриках. Много новых людей привлекли в Data Science ожидания от того, как мир изменят Big Data.
В результате этого быстро произошла «демократизация» корпоративных данных. Раньше данные принадлежали ИТ-службам. Маркетинг, продажи, бизнес-аналитики и руководители для получения отчетов обращались в ИТ-службу. Теперь у сотрудников появилась возможность работать с данными самостоятельно. Выяснилось, что прямой доступ сотрудников к данным способен повысить их продуктивность, обеспечить конкурентное преимущество.
Однако первое поколение основанных на технологии in-memory аналитических решений давало бизнес-пользователям ограниченные возможности использования данных. Они могли работать только с готовыми панелями и дашбордами. Технология in-memory позволяла им заглянуть в глубь любого показателя и увидеть, из чего он складывается. Но речь шла о показателях, которые определены заранее. Исследование ограничивалось уже размещенными на дашборде визуализациями. Такой способ использования данных, получивший название «направленная аналитика», не предполагал, что бизнес-пользователь займется подключением новых источников и самостоятельно будет создавать показатели и визуализации.
Следующим этапом на пути демократизации данных стало самообслуживание. Его идея заключалась в том, что бизнес-пользователи исследуют данные, создавая визуализации и вводя новые показатели самостоятельно.
Стоит заметить, к моменту, когда технология in-memory стала менять бизнес-аналитику, уже не было серьезных технологических препятствий к тому, чтобы обеспечить пользователям доступ ко всем данным. Возможно, у самых консервативных заказчиков был вопрос о целесообразности такой функции. Но мир уже повернулся в сторону желания «посчитать все». Теперь менеджерам, не имеющим математического образования и навыков программирования, требовался инструмент, который позволил бы говорить на языке данных.
Прямой доступ к данным открывал много новых возможностей и бизнес-аналитикам, которые могли выдвигать и проверять любые гипотезы, применять методы Data Science, выявлять зависимости, существование которых трудно предположить заранее. Появилась возможность объединять внутренние корпоративные данные с внешними – полученными из сторонних источников.
В сентябре 2014 г. компания Qlik выпустила второе поколение своей платформы, названной Qlik Sense. Она отличалась новым подходом к созданию визуализаций. Теперь стандартные визуализации можно было формировать на лету, просто перетаскивая на лист поля с нужными измерениями, что упростило исследование данных благодаря резкому сокращению цикла исследования. Проверка гипотезы занимала пару секунд.
Не исключено, что быстрый рост продаж аналитических платформ с самообслуживанием во многом был обусловлен простотой демонстрации. Если раньше заказчику приходилось принимать решение о покупке, рассматривая слайды презентации, то теперь он мог установить на компьютер программу, подключиться к источникам и за пару часов пройти весь путь от создания дашборда до открытия в нем своих данных.
Данные есть. Что дальше?
Технология in-memory оказала большое влияние на то, как сегодня бизнес пользуется информацией. Объединять и исследовать данные стало проще, что подтолкнуло бизнес к цифровой трансформации. Однако утверждать, что любая компания теперь запросто может осуществить цифровую трансформацию, нельзя.
С точки зрения технологий все просто до тех пор, пока объем изучаемых данных ограничивается несколькими Excel-таблицами. Когда речь идет об объединении миллиардов записей, то, скорее всего, задача окажется сложной с технической точки зрения, ее решение потребует экспертизы в области BI и инженерных находок. Особенно если при этом необходимо управлять качеством данных, что является обычной задачей для большей части средних и крупных компаний.
С точки зрения бизнеса все просто до тех пор, пока нужна отчетность или дашборды со стандартными для отрасли показателями. Иная ситуация с аналитической системой, к которой постоянно добавляются новые источники, вводятся дополнительные метрики, а в этих процессах задействованы специалисты из разных областей. Однако это уже не те трудности, которые преодолевали заказчики несколько лет назад. Уровень зрелости аналитических платформ таков, что даже если исходных данных очень много, то ждать подсчета показателей больше не нужно, а полученным цифрам можно доверять. В основе трансформации – вычисления in-memory.
Наверное, следующей технологией, способной изменить рынок аналитических решений, станут облачные платформы. Уже сегодня инфраструктура облачных сервис-провайдеров (CSP) в сочетании с набором предлагаемых услуг превращается в платформу управления данными.
——————————————————————
Ссылки
- IDC, Market Guide for In-Memory Computing Technologies, https://www.academia.edu/20067779/Market_Guide_for_In-Memory_Computing_Technologies
- Jim Gray. Distributed Computing Economics, https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/tr-2003-24.doc
