Перспективные направления развития средств видеоанализа

руководитель направления компьютерного зрения и анализа данных, компания «Техносерв»
За последние десять лет прогресс в видеоаналитике сделал огромный скачок вперед: появились мощные процессоры, в том числе графические (GPU), способные очень быстро выполнять операции линейной алгебры. Это дало новую жизнь нейронным сетям в обработке изображений – сверточные нейронные сети (или методы deep learning) позволяют классифицировать и распознавать предметы на изображениях точнее человека, и делают они это за считанные миллисекунды. Таким образом, появилась возможность обрабатывать видеопотоки в реальном времени.
Нейронные сети и задача распознавания
Сверточные нейронные сети – это искусственные нейронные сети, состоящие из большого количества так называемых перцептронов, которые представляют собой математическую функцию с параметрами. Собственно говоря, сверточными они называются потому, что имеют в своей структуре «сверточные слои», которые позволяют извлекать из данных локальные признаки, рассчитанные, например, для небольшой области изображения.
Такая архитектура сети оказалась успешной в распознавании изображений, звука и текста. Совокупности архитектуры сети и параметров составляют модель, которую затем нужно обучать. Например, если необходимо распознавать объекты на изображениях, должна использоваться обучающая выборка, состоящая из изображений с названием объектов или эталонами. При этом каждое изображение подается на вход модели, производятся расчет и сравнение результата с эталоном – рассчитывается ошибка, которая передается через все перцептроны обратно, изменяя параметры. Таких итераций может быть множество, например, при обучающей выборке 50 тыс. изображений, 500 эпох, необходимо провести 25 млн итераций.
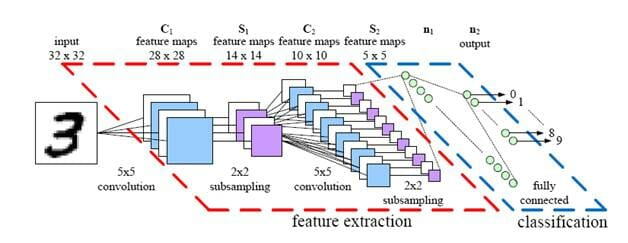
Технологический скачок открывает возможности для построения умных систем видеонаблюдения, способных понимать то, что происходит на видео, и моментально реагировать на события. Алгоритмы распознавания лиц, машин, детектирования людей, предметов, детектирования аварий – все это позволяет создать систему видеоаналитики нового поколения.
Алгоритм компьютерного зрения
Если мы ограничимся лишь теоретическим представлением работы данной системы, многие, существенные для практического воплощения детали ускользнут от внимания, потому разумнее будет обратиться к конкретным реализациям. Тем более что за подобного рода примерами использования технологии компьютерного зрения далеко ходить не придется – сегодня их можно найти и в России.
Так, на основе разработки алгоритмов компьютерного зрения, машинного обучения и сверточных нейронных систем «Техносерв» строит умную систему видеонаблюдения. Одной из ее основных задач является распознавание лиц в видеопотоках. Разработана архитектура сверточной нейронной сети, состоящей из нескольких десятков слоев: сеть обучалась на более чем 10 млн фотографий лиц людей, найденных в Интернете, модель обучалась различать лица разных людей.
Как работает алгоритм? Для начала на каждом кадре система находит лица людей с помощью другой нейронной сети, после чего эти лица вырезаются и изображения подаются на вход модели распознавания. На выходе модели получается биометрический шаблон: он представляет собой многомерный вектор размерностью больше 100 (фактически массив из более чем 100 вещественных чисел). Сформированные векторы имеют следующие свойства: они близки для лиц одного человека и существенно различаются для лиц разных людей. Имея базу данных фотографий лиц и построенных по ним биометрических шаблонов, мы с легкостью можем найти лица, самые близкие к исходному шаблону.
Точность распознавания системы составляет около 99,6% и является одной из самых высоких, судя по международному рейтингу систем распознавания, составленному University of Massachusetts.
Архитектура системы
Для построения масштабируемой системы видеонаблюдения и аналитики недостаточно одного алгоритма распознавания. Необходима оптимальная архитектура, позволяющая масштабировать систему линейно – в зависимости от количества камер и базы данных лиц. Целью являлось построение системы, способной обрабатывать видео более чем с 1000 камер и с возможностью расширения до 1 млн.
Представим себе, с каким объемом данных придется иметь дело. Каждая HD-камера 1080p создает поток в 8 Мбит/с, 24 кадр/с. Таким образом, для 1000 камер мы имеем 8 Гбит/с = 1 Гбайт/с, 24 000 кадр/с или 84 Тбайт в день и более 1 млрд кадров в день. А если таких камер будет 10 тыс. или 1 млн?
Очевидно, чтобы обработать такой объем информации, необходимо много «железа» и несколько центров обработки данных. Основная задача – это оптимизация всей системы таким образом, чтобы можно было сократить количество серверов и тем самым уменьшить стоимость всей системы.
За основу архитектуры взяты современные методы обработки больших данных в реальном времени. Верхнеуровневая архитектура представлена на схеме 1.
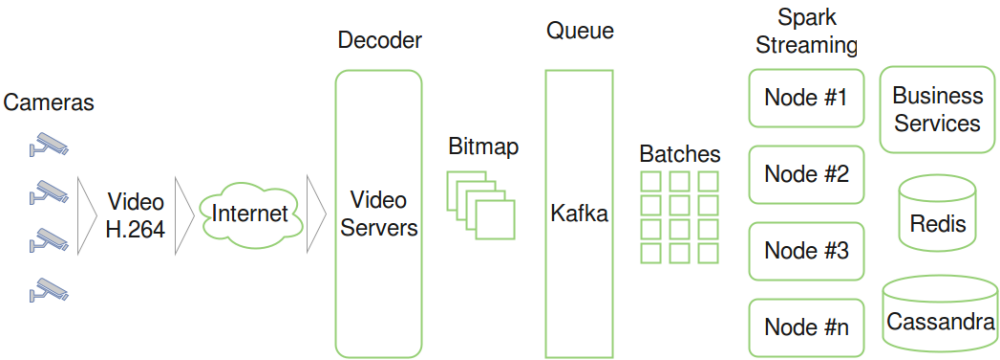
Основным звеном этой архитектуры являются связка Kafka и Spark Streaming. Kafka – это масштабируемая очередь, очень быстрая. Она позволяет на одном сервере обрабатывать до 2 млн сообщений в секунду. Spark Streaming читает из Kafka minibathes (пачки данных) из множества кадров и распределяет нагрузку между серверами кластера. Он позволяет представить такой вычислительный процесс в виде ацикличного направленного графа вычислений. Далее, вычисления распараллеливаются по узлам кластера.
Вся оперативная информация поднимается в in-memory-хранилище Redis. В нем хранятся, например, биометрические шаблоны лиц людей, информация о положениях объектов в нескольких последних кадрах и др.
Каждый граф вычислений Spark представляет собой последовательность действий (схема 2).
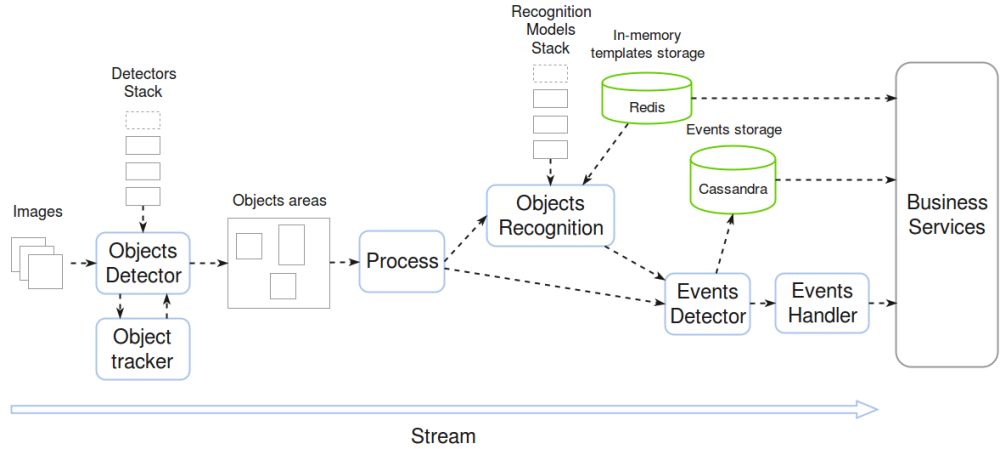
Первым делом кадр поступает в детектор объектов, который сначала проверяет, был ли данный объект в прошлом кадре. Если объект был, то нет необходимости его заново детектировать и распознавать, что существенно снижает нагрузку. Все это делается с помощью трэкера объектов – очень быстрого алгоритма сравнения последовательных кадров и отслеживания передвижения на нем объектов.
Детектор объектов на выходе создает разноцветный heatmap – карту объектов. Затем фотография каждого объекта вырезается и при необходимости отправляется в модуль распознавания. При распознавании лиц на выходе формируется вектор (как упоминалось ранее). Этот вектор сравнивается со всеми векторами базы данных, посредством чего находится ближайший к искомому. Поскольку для сравнения необходимо фактически считать всю базу (сделать fullscan), нужно хранить векторы лиц в памяти.
Затем данные обрабатывает триггер событий. Например, он может реагировать на появление разыскиваемого лица в кадре или при обнаружении пожара. Все события логируются в распределенной базе Cassandra.
«Железо» для параллельных вычислений
Алгоритмы распознавания и детектирования очень хорошо параллелятся, поэтому они выполняются на графических процессорах – GPU. Основное отличие GPU от CPU в том, что современный GPU имеет тысячи ядер, каждое из которых может работать в нескольких тысячах легковесных потоков. Например, чип Nvidia Tesla P100 имеет 3584 ядра, которые в сумме поддерживают до 125 тыс. потоков, выдавая скорость до 10,6 TFLOPS (10 600 млрд операций в секунду). Для сравнения: один из топовых процессоров Intel Xeon E5 2699v4 имеет 22 ядра и выдает до 0,9 TFLOPS, что в 11 раз меньше графического процессора от Nvidia. CPU лучше справляется с «тяжелыми» последовательными операциями, тогда как чип GPU предназначен для так называемых massively parallel computing (вычислений с большим количеством параллельных потоков).

При обработке большого количества потоков биометрических шаблонов возникает узкое место в производительности на шаге поиска похожих шаблонов в базе. Например, если в базе 100 млн людей и по десять фото у каждого, то получается 1 млрд биометрических шаблонов. С 1000 камер возможно иметь 24 тыс. шаблонов лиц (если на каждом кадре есть лицо) в секунду. Таким образом, нам необходимо сравнить 24 тыс. векторов с 1 млрд. Даже если держать базу в оперативной памяти, простым перебором это сделать невозможно. Нужен другой подход. Например, использование вероятностного метода понижения размерности многомерных данных (Locality-Sensitive Hashing – LSH). В этом методе используются хэш-функции специального свойства: они одинаковы либо близки для близких векторов и отличаются в противоположном случае. Эти функции позволяют сжать пространство векторов до меньшей размерности и построить хэш-таблицу, состоящую из бакетов (наборов) близких векторов. Следовательно, у нас появляется возможность найти близкие векторы за одну операцию сравнения. В секунду необходимо будет сделать всего лишь 24 тыс. сравнений (при максимальной производительности до 50 млн сравнений в секунду).
Эффективная многопоточная архитектура и множество оптимизаций позволяют в таком случае получить следующие параметры производительности системы: скорость обработки до 300 лиц в секунду; обработка 16 камер 1080р одновременно. При этом были использованы GPU Nvidia Titan X, CPU Intel Xeon E5 v3. В результате удалось добиться практически линейной масштабируемости системы. По расчетам инженеров, для обработки потоков с 10 тыс. камер понадобится около 600 GPU Titan X или 160 GPU Tesla K80. Таким образом, для построения системы необходимо применять «непростые кластеры», имеющие на борту как CPU, так и GPU.
Человеческий фактор
С повышением качества и скоростей алгоритмов компьютерного зрения, в частности глубинных нейронных сетей (deep learning), появляется возможность автоматизировать новые области человеческой деятельности и выйти на совершенно иной уровень роботизации. Для освоения новых рубежей необходимо сформировать новое мышление, культуру и ценности в ИТ-организациях, где на передний план будут выходить такие навыки, как глубокие знания математики и алгоритмов.
Для реализации умных систем нужно уметь работать со сложными математическими методами. Все это в конечном итоге приводит к повышению популярности и спроса на высококвалифицированных математиков, разработчиков и инженеров данных.
Чтобы обеспечить высокую производительность новых методов при работе с большими данными, необходимы гетерогенные системы, включающие в себя кластеры не только CPU, но и GPU.
