 Деятельность любого предприятия связана с генерацией огромных массивов данных. В настоящее время почти каждый станок, элемент технологической линии и тем более бизнес-процесс ежемесячно генерируют солидный объем сырых данных – от десятков мегабайт до сотен гигабайт. Большая их часть используется только единожды – для оперативного управления техпроцессами и стирается. Между тем грамотное применение этих данных способно принести предприятию выгоду. Какую именно и что для этого нужно предпринять?
Деятельность любого предприятия связана с генерацией огромных массивов данных. В настоящее время почти каждый станок, элемент технологической линии и тем более бизнес-процесс ежемесячно генерируют солидный объем сырых данных – от десятков мегабайт до сотен гигабайт. Большая их часть используется только единожды – для оперативного управления техпроцессами и стирается. Между тем грамотное применение этих данных способно принести предприятию выгоду. Какую именно и что для этого нужно предпринять?
Термин «большие данные» в последние пять лет звучит повсеместно, но за ним, как правило, скрываются разные системы. Среди специалистов бытует мнение, что к большим следует относить только данные, промежуточный результат обработки которых не помещается в оперативную память одного сервера. В этом случае приходится горизонтально масштабировать систему, что, в свою очередь, накладывает ограничения на алгоритмы, используемые для обработки. Еще один критерий – время, в течение которого должен быть получен ответ от системы и которое как раз и определяет, насколько нужно распараллелить процессы. По этому критерию выделяется отдельный подкласс систем так называемых быстрых данных (Fast data), их задача – свести к минимуму время получения ответа. Технически и алгоритмически они похожи на большие данные, но обрабатываемая в них информация хранится на более быстрых носителях или даже в оперативной памяти. Кроме того, большие данные часто являются разнородными, неструктурированными, поэтому с ними невозможно работать средствами обычных реляционных СУБД.
Зачем нам хранить и обрабатывать неструктурированные данные? Обо всем по порядку.
Перед тем как разбираться с платформами для обработки больших данных, попробуем понять выгоды, которые можно от этого получить, и как строить проект. Большинство заказчиков, начинающих проект, пытаются идти «от данных». Вопрос ставится так: «У нас есть такие и такие данные, помогите придумать, что с ними можно сделать». Подобные проекты рискуют вылиться в не очень продуктивную исследовательскую деятельность с неясными перспективами. Другая категория заказчиков приступает к созданию системы, не определив четко цели проекта. Поскольку конкретной бизнес-цели в этом случае нет, не определены и сроки. В такой ситуации исполнители начинают концентрироваться на построении самой лучшей платформы неизвестно для чего, зарываться в технические характеристики отдельных элементов оборудования, сравнивать по скорости диски, память и т. д. Проект вязнет в ненужных деталях и в конце концов, как правило, разваливается. Два этих типичных сценария – самая частая причина неудач в проектах по обработке больших данных.
Что представляет собой успешный BigData-проект? Определяющим фактором всегда должна быть бизнес-цель. Хорошо, если она может быть формализована и численно измерена. Например, текущий процент брака необходимо снизить до конкретного значения при сохранении прежнего уровня себестоимости продукции, свести к минимуму затраты на обслуживание оборудования, а также сократить время простоя технологической линии. Звучит фантастически, но это именно те задачи, которые можно решить с помощью анализа больших данных.
Главное, чтобы результат был значимым для бизнеса. Если понять, как уменьшить затраты на определенном этапе техпроцесса на 5%, то это много или мало? А если на 15%? Как только определен показатель, который следует улучшить, можно приступать к сбору данных. При этом важно учитывать, что поиск решения – итеративный процесс. Выдвигаем и проверяем гипотезу, по ходу понимаем, насколько близок ожидаемый результат, и процесс повторяется с новыми вводными. Как показывает опыт аналитических компаний в этом сегменте, до поиска приемлемого решения проходит шесть-семь циклов. В каждом очередном цикле меняют источники данных – одни исключают, другие добавляют, пробуют новые комбинации. Из сказанного следует два вывода.
Первый: в начале проекта невозможно точно прогнозировать, какие данные понадобятся для решения задачи. Зачастую нехватка данных, которые сочли неважными или слишком большими для сбора и хранения, не позволяет решить задачу в срок. Проект затягивается на время, необходимое для их накопления. Важно заранее собирать как можно больше данных, имеющих отношение к целевому технологическому процессу. Становится понятно, почему большие данные настолько разнородны. Если при сборе данных сразу их нормализовать с занесением в СУБД – часть неизбежно потеряется, и возможно, именно этого не хватит на этапе поиска решения. Поэтому рекомендуется хранить данные в «сыром» виде, как они поступают с датчиков, сенсоров и т. д. Процедуру извлечения проводить уже в процессе анализа.
Второй вывод состоит в том, что платформа, на которой накапливаются и анализируются данные, должна позволять хранить разнородные данные и гибко менять конфигурацию системы в процессе поиска решения. Чаще всего для этих целей используют продукты из экосистемы Hadoop. Процесс настройки и поддержания работоспособности экосистемы – задача нетривиальная.
Для решения таких задач компания Cisco предлагает серверы Cisco UCS, отличительная особенность которых – модель управления, нацеленная на максимальную автоматизацию рутинных задач администрирования. Серверы объединяются в наборы (кластеры), их конфигурацию можно задавать для кластера целиком с помощью сервисных профилей. Каждый профиль – это по сути XML-файл, в котором прописаны настройки, включая версии прошивок, настройки BIOS, идентификаторы сервера и параметры подключения к внешним сетям. Система, а в терминологии Cisco – серверная фабрика UCS, автоматически настраивает оборудование и следит за его конфигурацией. Такой подход значительно упрощает эксплуатацию кластеров, что и нужно проекту по работе с большими данными.
Чтобы упростить заказчику выбор платформы, Cisco создает и тестирует конфигурации систем под конкретные задачи. Описание этих конфигураций, названных CVD (Cisco Validated Design), доступно на сайте. Проработаны дизайны со всеми распространенными коммерческими дистрибутивами Hadoop – MapR, Cloudera, Hortonworks. Кстати, приобретение этих продуктов у Cisco дает возможность заказчику получить решение под ключ с единой технической поддержкой и услугами по настройке. Существуют дизайны и с другими производителями платформ для анализа данных – SAS, Splunk и т. д. Для удобства пользователей составлен документ – Cisco BigData Playbook, доступный по адресу http://cs.co/big-data-playbook. По сути, это справочник готовых дизайнов Cisco для работы с большими данными. Заказчику остается выбрать решения с учетом потребностей проекта и сосредоточиться на бизнес-задачах.
При построении кластера не следует забывать о сопутствующих системах – в первую очередь о платформе, на которой будут работать аналитики и созданные ими аналитические приложения. Часто для этого используют традиционную платформу виртуализации, что удобно, поскольку есть возможность гибко управлять платформой разработки – создавать и удалять рабочее окружение, сохранять слепки удачных конфигураций. Для этих задач компания предлагает гиперконвергентное решение Cisco Hyperflex. Поддержка сред виртуализации Vmware, Hyper-V и Docker обеспечивает заказчику гибкий выбор платформ и инструментов разработки. При этом BigData-кластер и кластер Hyperflex могут функционировать под управлением одной и той же фабрики UCS.
Еще один продукт для хранения и обработки больших данных – сервер хранения S3260. Неструктурированность данных и их большой объем приводят к необходимости иметь недорогое горизонтально масштабируемое объектное хранилище. Сервер S3260 служит основой для построения такого хранилища.
Важная особенность серверных решений Cisco UCS – единая модель управления вычислительной платформой, которая обеспечивает сквозную вертикальную интеграцию на всех уровнях: от серверов до приложений и сетевых сегментов, обеспечивающих их работу.
Таким образом, портфель серверных решений Cisco позволяет закрыть все потребности, возникающие при построении платформы для работы с большими данными. Кроме того, проработана большая группа индустриальных решений для оцифровки любых технологических процессов. Типовые протестированные конфигурации, описанные в публично доступных документах CVD, позволяют заказчикам не тратить время и деньги на создание архитектуры и дизайна платформы, а сосредоточиться на бизнес-задаче и получении максимальных выгод.
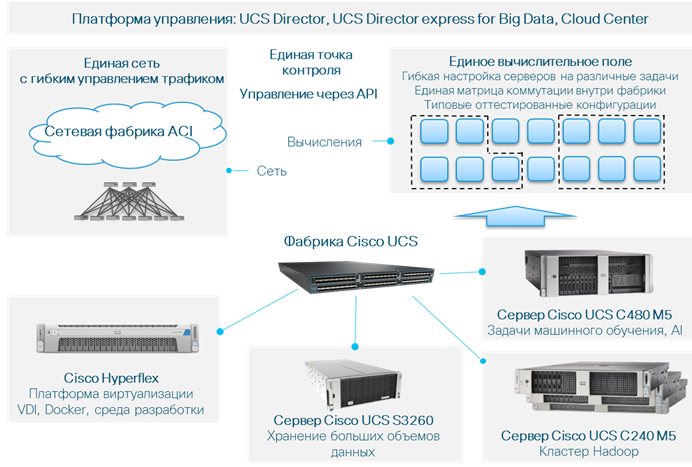
Рисунок. Продукты Cisco для построения системы хранения и обработки больших данных


