 На вебинаре «СХД в порядке» компания Naumen рассказала, как решить ключевые проблемы файловых хранилищ с помощью платформы Naumen Enterprise Search (NES), разработанной на основе микросервисной архитектуры. NES дает возможность агрегировать, структурировать и анализировать большие объемы данных из различных источников. Одна из основных функций решения – находить ответы на вопросы о данных, которыми располагает предприятие или компания.
На вебинаре «СХД в порядке» компания Naumen рассказала, как решить ключевые проблемы файловых хранилищ с помощью платформы Naumen Enterprise Search (NES), разработанной на основе микросервисной архитектуры. NES дает возможность агрегировать, структурировать и анализировать большие объемы данных из различных источников. Одна из основных функций решения – находить ответы на вопросы о данных, которыми располагает предприятие или компания.
Архитектура решения
В начале вебинара СТО компании Naumen Алексей Воронец представил архитектуру решения, каждый компонент которого можно масштабировать в зависимости от нагрузки и объемов данных конкретного заказчика. NES состоит из ядра, интеграционных инструментов с источниками данных и пользовательского интерфейса.
 В ядре представлен ETL-конвейер, задача которого – обработка сырых первичных данных. В процессе прохождения по конвейеру данные преобразуются, извлекается информация, формируются индексы, выявляются дубли документов и т. д. На основе происходящего в ETL-конвейере функционируют сервисы платформы.
В ядре представлен ETL-конвейер, задача которого – обработка сырых первичных данных. В процессе прохождения по конвейеру данные преобразуются, извлекается информация, формируются индексы, выявляются дубли документов и т. д. На основе происходящего в ETL-конвейере функционируют сервисы платформы.
Домом для ML-моделей эксперт назвал модуль AI (MOPS) – своего рода платформу внутри ядра, которая отвечает за размещение, обучение и выставление используемых API-моделей, например, связанных с векторизацией, извлечением сущностей.
Третий модуль в составе ядра – поисковые сервисы. Набор инструментов позволяет эффективно находить нужную информацию. Благодаря этому модулю возможны классический полнотекстовый поиск, семантический (по смыслу) и комбинированный. Предлагается также сравнение документов (по тексту, смыслу). Встроенный язык запросов позволяет уточнять, обеспечивает гибкость формируемых промтов. Предусмотрен механизм автоисправлений и подсказок.
Еще один модуль в составе ядра – для администрирования – аккумулирует в себе возможности журналирования, уведомления, планирования (отвечает за запуск отложенных вычислений). Здесь же осуществляется управление пользователями и краулерами (поисковыми роботами).
За интеграцию с источниками данных (один из основных компонентов системы) отвечают адаптеры. Их задача – получить данные из источника и передать на вход ETL-конвейеру. Есть пул адаптеров, предразработанных для популярных задач. У заказчиков имеется возможность создавать свои адаптеры.
 Поисковый интерфейс NES – то, с чем взаимодействует пользователь. Запрос вводится в классическую поисковую строку. В рамках выдачи показываются небольшие превью того, что нашлось. Предусмотрена возможность применения языка запросов, можно заглянуть в карточки найденных документов с детальной информацией. В этой же части платформы – отдел администрирования, где пользователи могут настраивать работу системы исходя из своих потребностей.
Поисковый интерфейс NES – то, с чем взаимодействует пользователь. Запрос вводится в классическую поисковую строку. В рамках выдачи показываются небольшие превью того, что нашлось. Предусмотрена возможность применения языка запросов, можно заглянуть в карточки найденных документов с детальной информацией. В этой же части платформы – отдел администрирования, где пользователи могут настраивать работу системы исходя из своих потребностей.
По словам эксперта, платформа предоставляет возможность решения широкого спектра проблем. На вебинаре речь шла о ключевых.
Рост, который не радует
 Первая проблема – рост данных. Как показывают исследования, объем данных в корпоративных хранилищах возрастает в среднем на 40–60% ежегодно. Аналитики Gartner включили увеличение объема данных в топ-3 вызовов, с которыми ежедневно сталкиваются корпорации.
Первая проблема – рост данных. Как показывают исследования, объем данных в корпоративных хранилищах возрастает в среднем на 40–60% ежегодно. Аналитики Gartner включили увеличение объема данных в топ-3 вызовов, с которыми ежедневно сталкиваются корпорации.
В результате повышается стоимость требуемых ресурсов, возникают риски хранения запрещенного контента (персональные данные, пароли). При этом компаниям сложно понять, что можно удалить, а что нет, непросто систематизировать представление о том, что вообще находится на хранении.
Решение NES состоит в возможности обеспечить индексацию и структурировать объем данных, предоставить пользователю интерфейс, помогающий обнаружить, что можно удалить, выявить информацию, которая дублируется. Для этого задействуются механизмы индексации, каталогизации, выделения чувствительной информации, касающейся персональных данных, реквизитов доступа и т. п.
Запертые данные
 Вторая проблема – запертые данные. Существенная часть хранящихся данных являются PDF без текста, картинами, сканами (как правило, такие архивы лежат мертвым грузом). Пользоваться подобным контентом в автоматическом режиме сложно.
Вторая проблема – запертые данные. Существенная часть хранящихся данных являются PDF без текста, картинами, сканами (как правило, такие архивы лежат мертвым грузом). Пользоваться подобным контентом в автоматическом режиме сложно.
Предлагаемое решение – OCR – применение различных алгоритмов для распознавания содержимого, качественной индексации. По словам специалистов, инструмент справляется с низким качеством документов, рукописными текстами, умеет работать с таблицами.
Наработки без доступа
Третья проблема – отсутствие доступа к знаниям в соседних отделах. Ключевые специалисты хранят в своих сетевых папках или глубоко в структуре уникальные наработки, инструкции, шаблоны, отчеты анализа. Сотрудники ориентируются по данным только внутри своей команды, отдела. В случае их увольнения или в период отпуска доступ к этим знаниям теряется либо значительно затруднен, что приводит к утрате экспертизы компании, повторению ошибок, дублированию работ.
Дублям нет числа
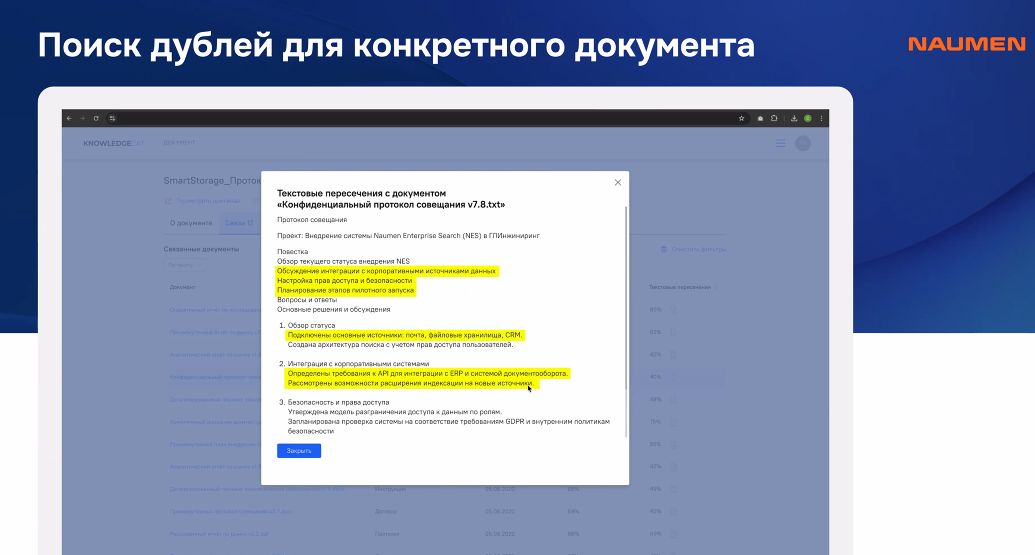
Четвертая проблема – большое количество дублей. Множественные копии документов, одинаковые версии, сохраненные в разных местах, частично измененные версии, без возможности понять актуальность данных приводят к потере времени на сверку, ошибкам на основе старых данных, неэффективному использованию и увеличению стоимости ресурсов.
На базе NES реализованы механизмы обнаружения полных, частичных дубликатов и похожих по содержанию документов. Открыв карточку документа, на вкладке «связи» можно увидеть список похожих с рассматриваемым документом и результат расчета, насколько они похожи. Доступны к просмотру также текстовые пересечения.
Структурные лабиринты
Пятая проблема – сложная структура хранения. Система папок, как и их наименование, зачастую определяется на местах, отсутствуют регламенты. Подобная ситуация затрудняет адаптацию новых сотрудников. Более того, как показывает практика, плохое структурирование способствует наращиванию дублей.
На основе платформы NES предлагается в автоматическом режиме каталогизировать пул документов. Каталог на основе правил означает, что проиндексированные документы автоматически группируются. Категории выделяются с помощью ML на базе смыслового содержания документов.
Конфиденциально или персонально
Шестая проблема – поиск чувствительных данных. Сотрудники копируют и хранят в личных папках сканы документов, содержащие конфиденциальные или персональные данные, аккумулируют пароли к ресурсам внутренним или клиентов. Все это может обернуться рисками нарушения Закона 152-ФЗ, утечками конфиденциальной информации, репутационными потерями и штрафами.
С помощью NES проблема решается посредством поиска в контенте паролей, названий ресурсов по правилам и ключевым словам. Предусмотрена возможность в категории каталога собрать и посмотреть все документы, в которых были найдены чувствительные данные.
Механизм фильтрации
Седьмая проблема – отсутствие инструментов фильтрации. Стандартные механизмы поиска в СХД и фильтрации примитивны, отмечают эксперты. У файлов нет полезных для фильтрации метаданных. В результате важная информация скрывается за неподходящими именами файлов и архивов.
На базе решения NES предлагается гибкий механизм фильтров, в частности, фасетных. Набор фильтров зависит от доступных документов. Дополнительная фильтрация обеспечивается на основе автоматически извлеченных сущностей из контента, в том числе из сканов. Например, фильтрация по ФИО, контрагенту, типу договора и пр.
Предусмотрена возможность выбирать и настраивать фильтры в зависимости от сценариев поиска (стандартные метаданные файлов, расширение, извлеченные из контента объекты).
Трудности поиска
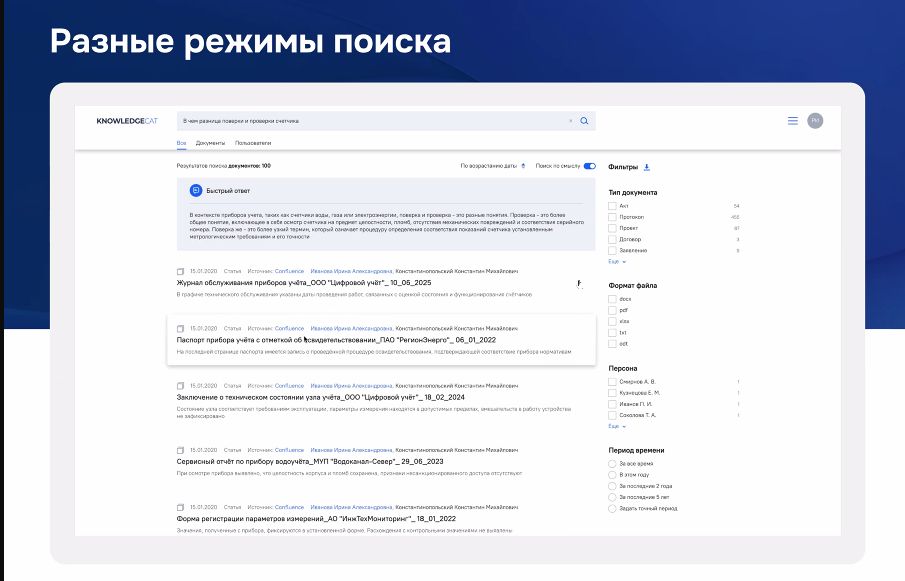
Восьмая проблема – нужный документ не находится. Даже имея инструмент для полнотекстового поиска, сотрудникам зачастую сложно обнаружить требуемый документ. Много однотипных файлов, среди которых непросто ориентироваться. Нередко сотрудники просто не знают, по каким ключевым словам искать. Отсюда и нежелание вновь тратить время на безуспешный поиск. Иной раз проще принять решение, не имея на руках полной информации.
Одно из преимуществ решения NES – различные режимы поиска: полнотекстовый с фильтрами и логическими операторами, семантический, если сотрудник знает примерную тему. Предусмотрена генерация ответа на вопрос (RAG) на естественном языке, если нужен быстрый краткий ответ.
Недели ручного труда
Девятая проблема – трудозатраты на аудит и комплаенс, которые могут составлять недели ручного труда. Проверки, организуемые регуляторами (ФСТЭК, Роскомнадзором, ФНС), внутренний аудит требуют предоставления всех документов по теме либо персоне за определенный период.
На этапе подготовки к аудиту в поте лица трудятся юристы, сотрудники ИБ- и ИТ-отделов, конечно, если компания хочет избежать штрафа либо репутационных потерь, например, из-за неполного предоставления информации или обнаружения незащищенных персональных данных.
На платформе NES реализован единый поиск по всем хранилищам. Пользователям не составит труда обнаружить документы с персональными данными или чувствительной информацией. За секунды с учетом прав доступа будут сформированы полные и обоснованные выборки документов.
Остров в океане данных
Десятая проблема – поиск по СХД как «отдельному острову в океане данных». После внедрения Naumen Enterprise Search сотрудникам все равно приходится отдельно искать нужное в почте, СЭД, KMS, ERP, тикет-системах. Контекст теряется, поиск остается фрагментированным.
 Еще одно преимущество NES в том, что платформа не ограничивается СХД – благодаря адаптерам может подключаться к любым корпоративным системам (базам знаний, базам данных, ERP, CRM, корпоративным порталам). Все, для чего можно написать адаптер, может стать источником для платформы NES, способной извлекать данные в любом формате.
Еще одно преимущество NES в том, что платформа не ограничивается СХД – благодаря адаптерам может подключаться к любым корпоративным системам (базам знаний, базам данных, ERP, CRM, корпоративным порталам). Все, для чего можно написать адаптер, может стать источником для платформы NES, способной извлекать данные в любом формате.
NES предоставляет единую точку входа для поиска по всем корпоративным системам. И для пользователя уже не столь важно, какой алгоритм используется в том или ином случае.
