Когда речь заходит о внедрении искусственного интеллекта в промышленность, многие представляют себе абстрактные концепции или футуристические сценарии. Однако реальность оказывается гораздо практичнее. Наглядным примером на недавно прошедшем митапе поделились эксперты компании CodeInside, представив пилотный проект по внедрению платформы Dacora AI в , который продемонстрировал, как цифровые ассистенты могут кардинально изменить работу с технической документацией и ускорить инженерные процессы.
Проблема, с которой столкнулся институт, знакома многим промышленным предприятиям, за десятилетия работы был накоплен огромный архив исследований, технологических регламентов, протоколов испытаний, начиная с 1960-х годов. Этот архив безусловно имел ценность, но практически не использовался в повседневной работе. Инженеры тратили часы на поиск нужной информации в бумажных томах и электронных хранилищах, а сложность доступа означала, что накопленный опыт фактически лежал мёртвым грузом. Ситуацию усугублял вопрос безопасности так как данные содержали коммерческую тайну, что полностью исключало возможность использования публичных облачных ИИ-решений вроде ChatGPT, которые обучаются на загружаемой информации и могут привести к ее утечке.
 В качестве решения НИИК выбрал решение в виде платформы Dacora AI. Вместо развертывания гигантской языковой модели, «знающей Шекспира и Кафку», как с иронией отмечает Павел Колодец, заместитель генерального директора по цифровой трансформации НИИК, была выбрана дистиллированная модель на 40 миллиардов параметров, которая затем дообучалась исключительно на внутренних данных института. Ключевым принципом стало локальное развертывание. Система работает полностью внутри защищенного контура компании, без какого-либо доступа в интернет, что гарантирует абсолютную сохранность коммерческой тайны и полный контроль над обработкой информации. С технической точки зрения, для развертывания потребовался сервер с GPU H100 от Nvidia, при этом общая стоимость решения оказалась на порядок ниже предложений крупных системных интеграторов, став одним из решающих факторов для НИИК.
В качестве решения НИИК выбрал решение в виде платформы Dacora AI. Вместо развертывания гигантской языковой модели, «знающей Шекспира и Кафку», как с иронией отмечает Павел Колодец, заместитель генерального директора по цифровой трансформации НИИК, была выбрана дистиллированная модель на 40 миллиардов параметров, которая затем дообучалась исключительно на внутренних данных института. Ключевым принципом стало локальное развертывание. Система работает полностью внутри защищенного контура компании, без какого-либо доступа в интернет, что гарантирует абсолютную сохранность коммерческой тайны и полный контроль над обработкой информации. С технической точки зрения, для развертывания потребовался сервер с GPU H100 от Nvidia, при этом общая стоимость решения оказалась на порядок ниже предложений крупных системных интеграторов, став одним из решающих факторов для НИИК.
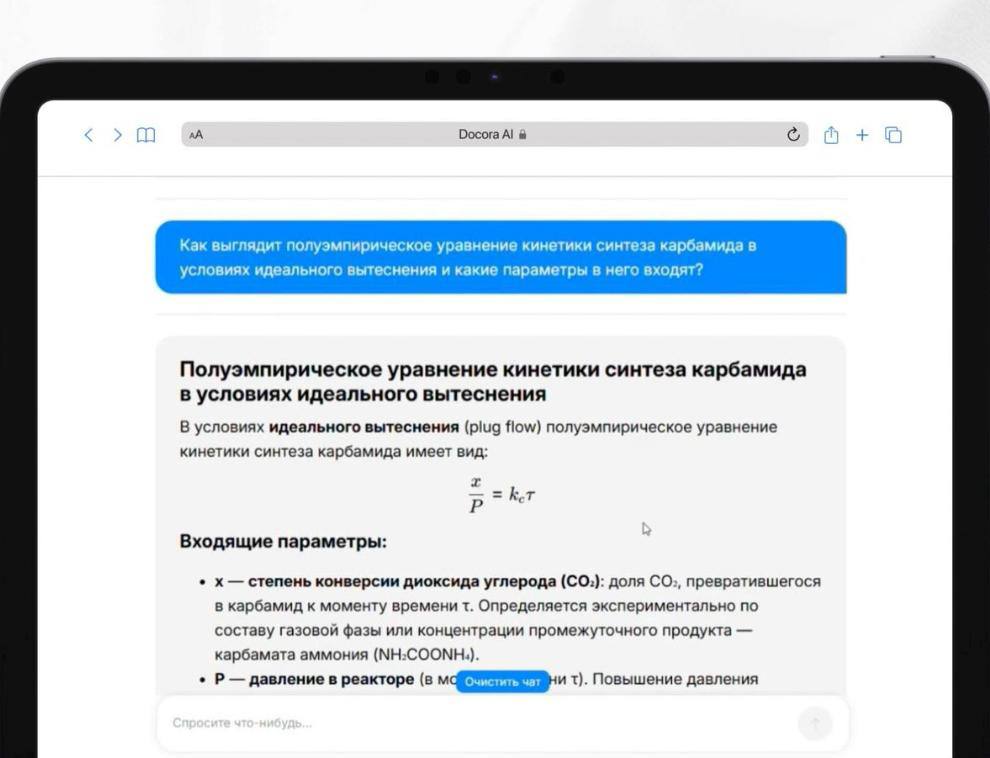
Платформа позиционируется как цифровой эксперт, с которым можно общаться на естественном языке, как с коллегой. Инженеры задают вопросы в привычной формулировке, так как система понимает профессиональную терминологию, включая специфические химические термины и формулы, а каждый ответ сопровождается ссылкой на первоисточник, позволяя всегда проверить, откуда была взята информация.
По заявлениям экспертов, в отличие от публичных моделей, Dacora AI не «галлюцинирует» и строго следует предоставленным документам, не выдумывая ответов. Пилотный проект, хотя и не являлся полномасштабным внедрением (оно запланировано на 2026 год), уже показал некоторые результаты. В тестировании участвовали около 20 человек. После первоначальной настройки, включавшей работу над специфической терминологией (например, слово «плав» в контексте карбамида система сначала интерпретировала как «плавание»), удалось достичь более 90% удовлетворенности пользователей. Система научилась работать не только с текстом, но и с химическими формулами, схемами и другими профессиональными элементами документации. Как отмечает Олег Ведерников, руководитель R&D направления CodeInsight, разработчика платформы: «Мы поняли, что разные слова в разных индустриях могут нести различный смысл. Здесь нужно именно работать со смысловой интерпретацией того или иного слова».
 Обеспечение безопасности соответствовало стандартным промышленным практикам. Система функционирует в изолированном контуре без внешнего подключения, что исключает передачу данных вовне. При необходимости модель может получить контролируемый выход в интернет через защищенный туннель, который настраивает служба информационной безопасности заказчика, а права доступа разграничивают на уровне документов и отдельных их фрагментов. Что касается интеграции, система работает с любыми базами данных через открытые API, подключается к файловым хранилищам и веб-сервисам. Она обрабатывает PDF, Excel, изображения, извлекая семантику даже с графических материалов. Архитектура включает каскад специализированных моделей для обработки текста, работы с формулами, оценки релевантности. Под капотом работает не одна большая модель, а каскад специализированных решений: реранкеры оценивают релевантность, эмбеддеры преобразуют данные, отдельные модули обрабатывают изображения или синтезируют речь.
Обеспечение безопасности соответствовало стандартным промышленным практикам. Система функционирует в изолированном контуре без внешнего подключения, что исключает передачу данных вовне. При необходимости модель может получить контролируемый выход в интернет через защищенный туннель, который настраивает служба информационной безопасности заказчика, а права доступа разграничивают на уровне документов и отдельных их фрагментов. Что касается интеграции, система работает с любыми базами данных через открытые API, подключается к файловым хранилищам и веб-сервисам. Она обрабатывает PDF, Excel, изображения, извлекая семантику даже с графических материалов. Архитектура включает каскад специализированных моделей для обработки текста, работы с формулами, оценки релевантности. Под капотом работает не одна большая модель, а каскад специализированных решений: реранкеры оценивают релевантность, эмбеддеры преобразуют данные, отдельные модули обрабатывают изображения или синтезируют речь.
На данный момент команда планирует развитие мультиагентной системы с единым ядром. Это позволит создавать универсальных агентов для общих задач и специализированных помощников для конкретных индустрий или процессов. «Наша цель — снизить порог входа для пользователей, чтобы система валидно обрабатывала даже самые нестандартные вопросы и давала релевантные ответы», — поясняет Олег.
В ходе дискуссии эксперты обозначили три основные ступени развития промышленного ИИ: ассистент, аналитик и исследователь. Как отметил Павел, сегодня промышленность в большинстве случаев находится именно на этапе ассистента, который помогает находить информацию, отвечает на вопросы и структурирует данные.
Следующим закономерным шагом для отрасли станет переход к уровню аналитика, где система сможет выполнять предварительные расчеты, сравнивать сценарии и предлагать обоснованные варианты решений. Высшая ступень исследователя предполагает способность ИИ генерировать новые гипотезы и участвовать в научном поиске.
Сам по себе продукт не является уникальным и как было отмечено ранее, ИИ агенты, копилоты и подобные продукты-ассистенты начинают внедряться повсеместно, тем не менее как точно сформулировал Павел: «Ассистент, который мы создаём, он поднимает знания и доносит их до каждого в удобной форме». В этом, пожалуй, и заключается главная ценность подобных решений. Они оживляют накопленные знания и тем самым ускоряют инженерные процессы, освобождая специалистов для творческих и аналитических задач, где человеческий интеллект пока остается незаменимым.
Артем Пермяков, Connect
