 На вебинаре «Особенности внедрения собственного LLM-сервиса внутри компании», организованном компанией Positive Technologies, эксперты раскрыли детали развертывания LLM, поделились опытом внедрения. Особое внимание был уделено сравнению вариантов public API и self-hosted. На какие аргументы ориентироваться, чтобы не ошибиться с выбором в каждом конкретном случае? И почему не стоит искать лучшую из доступных моделей?
На вебинаре «Особенности внедрения собственного LLM-сервиса внутри компании», организованном компанией Positive Technologies, эксперты раскрыли детали развертывания LLM, поделились опытом внедрения. Особое внимание был уделено сравнению вариантов public API и self-hosted. На какие аргументы ориентироваться, чтобы не ошибиться с выбором в каждом конкретном случае? И почему не стоит искать лучшую из доступных моделей?
В начале вебинара руководитель группы специальных проектов компании Positive Technologies Алексей Пехтерев назвал направления, на которых LLM может принести пользу бизнесу: сегмент, где разрабатываются фичи на основе моделей, общие кейсы, где LLM позволяет решать рутинные задачи (например, переформатировать текст, написать код и т. д.), оптимизация внутренних процессов (в частности, полуавтоматизация) в маркетинге, HR.
В работе с LLM почти 47% пользователей составляют новички, 33% – экспериментаторы, 11% – скептики, около 8% – практики и всего 1% – эксперты.
По словам представителя Positive Technologies, потенциал LLM для бизнеса бесспорен. Понимание этих возможностей привело к тому, что в Positive Technologies пользуются LLM и продолжают их внедрять для оптимизации и ускорения внутренних процессов, а также для развития новых продуктовых фичей. Компания охотно делится своим опытом.
Преимущества проприетарных моделей
Один из ключевых вопросов на старте проектов с LLM ‒ что выбрать: публичный API или Self-hosted LLM? На первый взгляд, ответ очевиден. Зачем отравляться в самостоятельное плавание, если можно воспользоваться проприетарными моделями провайдеров? Бесспорных преимуществ такого варианта немало.
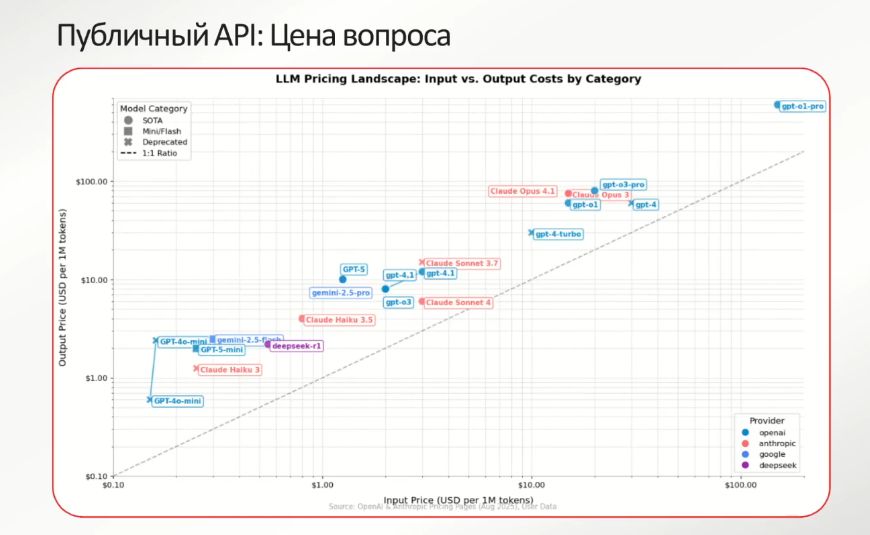 Лучшее качество генерации из возможных (никакой оупенсорс за этими моделями не угонится, они соревнуются между собой и со временем улучшаются), простота интеграции (элементарно воспользоваться – достаточно пополнить счет). Вендор отвечает за SLA. Развитое комьюнити вокруг крупных поставщиков, поэтому пользователи всегда подскажут, какая модель работает лучше и для каких задач.
Лучшее качество генерации из возможных (никакой оупенсорс за этими моделями не угонится, они соревнуются между собой и со временем улучшаются), простота интеграции (элементарно воспользоваться – достаточно пополнить счет). Вендор отвечает за SLA. Развитое комьюнити вокруг крупных поставщиков, поэтому пользователи всегда подскажут, какая модель работает лучше и для каких задач.
Благосклонна к потребителям и политика Pay-as-you-go, когда платить нужно только за Input и Output токены по мере использования сервиса. Что касается цен, то Output-токены всегда обходятся дороже, чем Input-. Их генерация занимает больше времени, выше объем ресурсов, утилизируемых для генерации и обработки Output-токенов.
 Наглядный расчет фичи привел Алексей Пехтерев на примере гипотетического чат-бота в вакууме с 1 тыс. активных пользователей в день, каждый из которых отправляет в среднем десять сообщений в сутки. Длина входного сообщения составляет 2 тыс. токенов. Модель генерирует длинный Output (2 тыс. токенов на выход). Если перевести все это в цены, то в месяц на модели GPT-5 выходит 6750 долл., на модели GPT-5 mini – 1350 долл. (вполне приемлемо, считает эксперт). Для задач, вроде чат-ботов, которые не требуют сверхзнаний высокоуровневых моделей, достаточно мини- и нановерсий LLM.
Наглядный расчет фичи привел Алексей Пехтерев на примере гипотетического чат-бота в вакууме с 1 тыс. активных пользователей в день, каждый из которых отправляет в среднем десять сообщений в сутки. Длина входного сообщения составляет 2 тыс. токенов. Модель генерирует длинный Output (2 тыс. токенов на выход). Если перевести все это в цены, то в месяц на модели GPT-5 выходит 6750 долл., на модели GPT-5 mini – 1350 долл. (вполне приемлемо, считает эксперт). Для задач, вроде чат-ботов, которые не требуют сверхзнаний высокоуровневых моделей, достаточно мини- и нановерсий LLM.
На рынке наблюдается тенденция к тому, что инструменты вокруг LLM, которыми модели могут пользоваться (например, осуществлять поиск в Интернете), стоят недешево – во всяком случае, кратно дороже самой LLM. И такой тренд в ближайшие годы сохранится, прогнозируют специалисты.
Лимиты и другие ограничения
Поскольку LLM требует больших объемов «железа» для своей производительности, то очевидное ограничение – лимиты по использованию API. Обычно вендоры устанавливают лимиты в виде числа запросов, которые пользователь может отправить в минуту, и количества токенов. Правда, олитики вендоров различаются. Чем больше пользоваться API, чаще пополнять счет и оставаться лояльным клиентом как можно дольше, тем шире возможности и выше уровень.
 Вендоры ориентируются на уровень приоритета, когда они готовы обеспечить предоставление SLA. Но для этого пользователю заранее надо определиться с тем, какова возможная нагрузка, в частности, сколько токенов будет проходить через минуту от запросов, выбрать модель, которой планируется воспользоваться, и, по словам эксперта, «закоммититься» (от англ. commitment – обязательство) с провайдером на один-три-шесть или 12 месяцев (достаточно продолжительный срок).
Вендоры ориентируются на уровень приоритета, когда они готовы обеспечить предоставление SLA. Но для этого пользователю заранее надо определиться с тем, какова возможная нагрузка, в частности, сколько токенов будет проходить через минуту от запросов, выбрать модель, которой планируется воспользоваться, и, по словам эксперта, «закоммититься» (от англ. commitment – обязательство) с провайдером на один-три-шесть или 12 месяцев (достаточно продолжительный срок).
Если уровня приоритета (Priority Tier) нет, то можно столкнуться с такой проблемой, как, например, перегрузка сервиса. Стоит учитывать и тот факт, что многие сервисы недоступны из Российской Федерации (доступ к ним ограничен и из некоторых других стран).
Кроме того, может возникнуть ситуация, когда для работы системы модель генерировала контент, который провайдер считает недопустимым по тем или иным причинам. Один из распространенных примеров – пентест. Модели зачастую не готовы генерировать подобный контент – считают его нелегитимным действием. В таких случаях приходится прибегать к ухищрениям.
Как известно, любой провайдер не застрахован от непредвиденных обстоятельств. Например, у deepseek на старте одной из моделей пришлось отключить пополнение счета – вендор не рассчитал наплыв пользователей. Модель не выдержала количества запросов и не отвечала очень долго. На Input-токены тратились деньги со счета, Output-токены не возвращались, поэтому вендор был вынужден отключить опцию пополнения счета.
Однако основным фактором в вопросе, какому подходу отдать предпочтение, является приватность данных – остается ли в тайне диалог с LLM. И это, пожалуй, главный аргумент в пользу выбора варианта Self-hosted LLM. В смысле безопасности доступны разные варианты. Но никто, как показывает практика, не может гарантировать отсутствие утечек.
На другой чаше весов
Что может предложить собственный хостинг? Прежде всего данные остаются внутри компании под полным контролем. Затраты фиксируемые, прогнозируемые и не зависят от объемов использования. В качестве конкурентного преимущества можно рассматривать глубокую кастомизацию.
Однако для реализации такого подхода требуется приложить усилия – нужны команда и время, на быстрый старт рассчитывать не приходится. Качество тоже оставляет желать лучшего.
 При этом оба подхода имеют право на существование. Публичному API стоит отдать предпочтение в случаях прототипирования и проверки гипотез (например, надо проверить, сможет ли самая умная LLM решить конкретную задачу качественно), готовности продолжительно сотрудничать с провайдером либо когда данные не настолько чувствительны, что их можно отправлять третьему лицу.
При этом оба подхода имеют право на существование. Публичному API стоит отдать предпочтение в случаях прототипирования и проверки гипотез (например, надо проверить, сможет ли самая умная LLM решить конкретную задачу качественно), готовности продолжительно сотрудничать с провайдером либо когда данные не настолько чувствительны, что их можно отправлять третьему лицу.
Собственный хостинг в приоритете для тех, кто поставил перед собой цель разрабатывать ноу-хау продукты или фичи, в основе которых лежит LLM, или не готов отправлять свои данные на сторону.
 Если резюмировать аргументы в пользу выбора варианта self-hosted, то можно привести следующий перечень: в обращении строго конфиденциальные данные (коммерческая тайна и т. п.), планируется высокая и постоянная нагрузка длительное время, при которой расходы на публичный API станут невыгодными, нужен экспертный продукт/фича в уникальной нишевой сфере (внутренняя база знаний, агентские системы, автоматизирующие внутреннюю экспертизу), для продукта/фичи желательно самим контролировать минимальную задержку.
Если резюмировать аргументы в пользу выбора варианта self-hosted, то можно привести следующий перечень: в обращении строго конфиденциальные данные (коммерческая тайна и т. п.), планируется высокая и постоянная нагрузка длительное время, при которой расходы на публичный API станут невыгодными, нужен экспертный продукт/фича в уникальной нишевой сфере (внутренняя база знаний, агентские системы, автоматизирующие внутреннюю экспертизу), для продукта/фичи желательно самим контролировать минимальную задержку.
В поисках правильной, а не лучшей
 Тем, кто столкнулся с трудностями выбора модели, эксперт дал несколько рекомендаций. Не забывать, что цель не в том, чтобы найти лучшую модель, а в том, чтобы определиться с правильной моделью для конкретных обстоятельств. Критериев оценки в данном случае несколько: насколько хорошо модель справляется с вашей задачей, размер модели и «железо» (что можно себе позволить), лицензионный аспект (можно ли легально использовать модель в коммерческих целях), наличие экосистемы и поддержки (насколько активно сообщество вокруг модели).
Тем, кто столкнулся с трудностями выбора модели, эксперт дал несколько рекомендаций. Не забывать, что цель не в том, чтобы найти лучшую модель, а в том, чтобы определиться с правильной моделью для конкретных обстоятельств. Критериев оценки в данном случае несколько: насколько хорошо модель справляется с вашей задачей, размер модели и «железо» (что можно себе позволить), лицензионный аспект (можно ли легально использовать модель в коммерческих целях), наличие экосистемы и поддержки (насколько активно сообщество вокруг модели).
