 Оркестрация контейнеров в Kubernetes давно стала отраслевым стандартом, однако работа с ресурсоемкими AI/ML и Big Data нагрузками требует особого подхода – от настройки специализированных кластеров с GPU до контроля кастомных ресурсов и обеспечения безопасности при работе с многогигабайтными образами. В рамках вебинара Дмитрий Евдокимов, основатель и технический директор компании Luntry, детально разобрал ключевые особенности защиты таких сред. Спикер рассказал о новых возможностях Kubernetes, адаптированных под задачи искусственного интеллекта, выделил основные домены безопасности, а также объяснил, почему стандартные подходы к безопасности не работают в условиях больших данных и специфики AI-стека.
Оркестрация контейнеров в Kubernetes давно стала отраслевым стандартом, однако работа с ресурсоемкими AI/ML и Big Data нагрузками требует особого подхода – от настройки специализированных кластеров с GPU до контроля кастомных ресурсов и обеспечения безопасности при работе с многогигабайтными образами. В рамках вебинара Дмитрий Евдокимов, основатель и технический директор компании Luntry, детально разобрал ключевые особенности защиты таких сред. Спикер рассказал о новых возможностях Kubernetes, адаптированных под задачи искусственного интеллекта, выделил основные домены безопасности, а также объяснил, почему стандартные подходы к безопасности не работают в условиях больших данных и специфики AI-стека.
Новые возможности Kubernetes для AI/ML-нагрузок
Kubernetes не стоит на месте. С каждым новым релизом, новыми фичами он все больше адаптируется под современные вызовы и потребности команд, которые запускают AI/ML-нагрузки. Спикер выделил три таких направления:
- Node Feature Discovery – автоматическое определение возможностей узлов, например, наличие GPU, NPU;
- Container Device Interface – механизм проброса устройств (видеокарт, NPU) в контейнеры;
- Checkpoint/Restore – механизм сохранения и восстановления состояния процессов.
Все они, конечно, не являются заточенными именно под AI/ML-задачи, их применение шире. Но каждый из них привносит свои преимущества при работе с большими нагрузками.
Если вы не обновляете свои кластеры, долго держите их на старых версиях, например, на 1.14, 1.20 (последняя версия сейчас 1.35), то вы этих преимуществ не получите. Ваша AI/ML-нагрузка будет использоваться и эксплуатироваться неэффективно. Поэтому необходимо обновлять окружение соответствующим образом.
Разбор по доменам безопасности Kubernetes
Контроль состояния кластера
В рамках этого домена необходимо контролировать актуальность используемых версий. Kubernetes-сообщество поддерживает последние три релиза. Все остальные не получают никаких улучшений, исправлений, CVE. На сегодняшний день это 1.35, 1.34 и 1.33. Если в вашей компании используются кластеры более низких версий, улучшения вам недоступны.
Помимо актуальности версий необходимо контролировать системные компоненты Kubernetes, чтобы они были обновлены и не содержали известных уязвимостей. Для этого Kubernetes выпускает официальные CVE-отчеты, где можно сравнивать kube-proxy, kubelet, kube-controller-manager, kube-apiserver на предмет использования исправленных, неуязвимых версий.
Контроль соответствия кластера стандартам
Появляется специфика работы с чувствительными данными. Необходимо учитывать требования GDPR и PCI DSS. В России активно развивается риторика в сфере искусственного интеллекта и начинают появляться первые приказы. Данным, с которыми ведется работа, будет уделяться особое внимание, вероятно, с выделением отдельных контуров. Как и в случае с персональными данными, механизмы работы будут аналогичными.
Контроль ресурсов
 Использование Kubernetes для AI-нагрузок усиливает потребность в контроле всех ресурсов кластера. Необходимо отслеживать запросы (request) и лимиты (limits), чтобы выделять нагрузкам ровно столько ресурсов, сколько требуется.
Использование Kubernetes для AI-нагрузок усиливает потребность в контроле всех ресурсов кластера. Необходимо отслеживать запросы (request) и лимиты (limits), чтобы выделять нагрузкам ровно столько ресурсов, сколько требуется.
Поскольку стек разнороден, появляются собственные операторы с кастомными ресурсами. Контроль над ними становится критически важным. В компаниях разрабатываются свои операторы для управления цензором, PVC, Jupyter Notebooks и другими сущностями. На этом уровне можно контролировать значения, выставляемые внутри компании. Поэтому обязательны Policy Engine или решения, позволяющие управлять любыми Kubernetes-ресурсами.
Инженеры собирают инфраструктуру из нужных компонентов, в том числе open-source операторов. Специалистам по безопасности необходимо сосредоточиться не только на подах, деплойментах и сервисах, но и на кастомных ресурсах.
С развитием Kubernetes появился встроенный движок для проверки кастомных ресурсов – Validation Admission Policy. В новых версиях его можно использовать.
В Security Whitepaper есть раздел о защите хранилищ и PersistentVolume, где указано, что только определенные нагрузки могут монтировать соответствующие хранилища. Без такого контроля Data Science-инженер может смонтировать хранилище с данными, к которым не должен иметь доступа. Например, если в одном хранилище находятся анонимизированные данные, а в другом – неочищенные и неанонимизированные. При свободном доступе к PersistentVolume он сможет подключить оба, что приведет к утечке.
С помощью Validation Admission Policy или Policy Engine можно регулировать, какие нагрузки какие PersistentVolume монтируют: конкретная нагрузка в заданном окружении получает доступ только к разрешенным хранилищам. Это важно учитывать, иначе сотрудник может получить информацию, которая ему недоступна.
Аудит и логи
 Kubernetes Audit Log «из коробки» позволяет мониторить операции с любыми Kubernetes-ресурсами – все, что проходит через Kubernetes API. Единственное, что нужно учитывать, это грамотно написанная политика аудита. Если она составлена неправильно, вы получите ограниченную картину, которая не будет отражать все происходящее.
Kubernetes Audit Log «из коробки» позволяет мониторить операции с любыми Kubernetes-ресурсами – все, что проходит через Kubernetes API. Единственное, что нужно учитывать, это грамотно написанная политика аудита. Если она составлена неправильно, вы получите ограниченную картину, которая не будет отражать все происходящее.
Особо стоит выделить историю с плейбуками для ML/AI-кластеров, поскольку там долгоживущие процессы. Работа идет с большими данными, и требуется соответствующая реакция. Если просто останавливать или отключать процессы, можно потерять данные и наработки за длительный промежуток времени. Поэтому, с точки зрения реагирования и операций, команда, которая за это отвечает, либо внешний SOC должны учитывать эту специфику. Заранее прописывайте соответствующие политики и плейбуки, иначе работа, на которую было потрачено немало времени, будет напрасной.
Безопасность образов
При обсуждении Big Data в первую очередь отмечаются большие образы. В проектах встречаются образы размером 150 ГБ, 90 ГБ, несколько десятков гигабайт. В таких объемах основную долю занимают статические данные, однако присутствует и значительное количество зависимостей, что влечет за собой множество уязвимостей.
Следует стремиться к минималистичным образам, использовать тонкие образы, например дистролессы, без лишних компонентов. Это повысит уровень безопасности и сделает образы компактнее при загрузке, выгрузке и запуске.
Начиная с версии 1.31 в альфе доступен фича-гейт ImageVolume, позволяющий подключать отдельный образ в качестве тома. В него можно поместить конфигурации, нейросети, фиды, лей-модели, датасеты и прочие данные. Такой подход разделяет образ с кодовой базой и образы для хранения статической информации, используемой для Big Data. Кроме того, это решает проблему со сканерами безопасности. При сканировании образа размером 25 гигабайт для распаковки и анализа требуется примерно столько же места, для образа в 150 ГБ – около 150 ГБ. Резервировать такие объемы под сервис анализа никто не готов по экономическим и техническим причинам.
Разделение статических данных и кодовой базы позволяет хранить часть образов в отдельном репозитории без сканирования анализаторами образов, так как в этом нет смысла. Кодовая база будет проходить сканирование и анализ в обычном режиме.
Уязвимости AI-стека
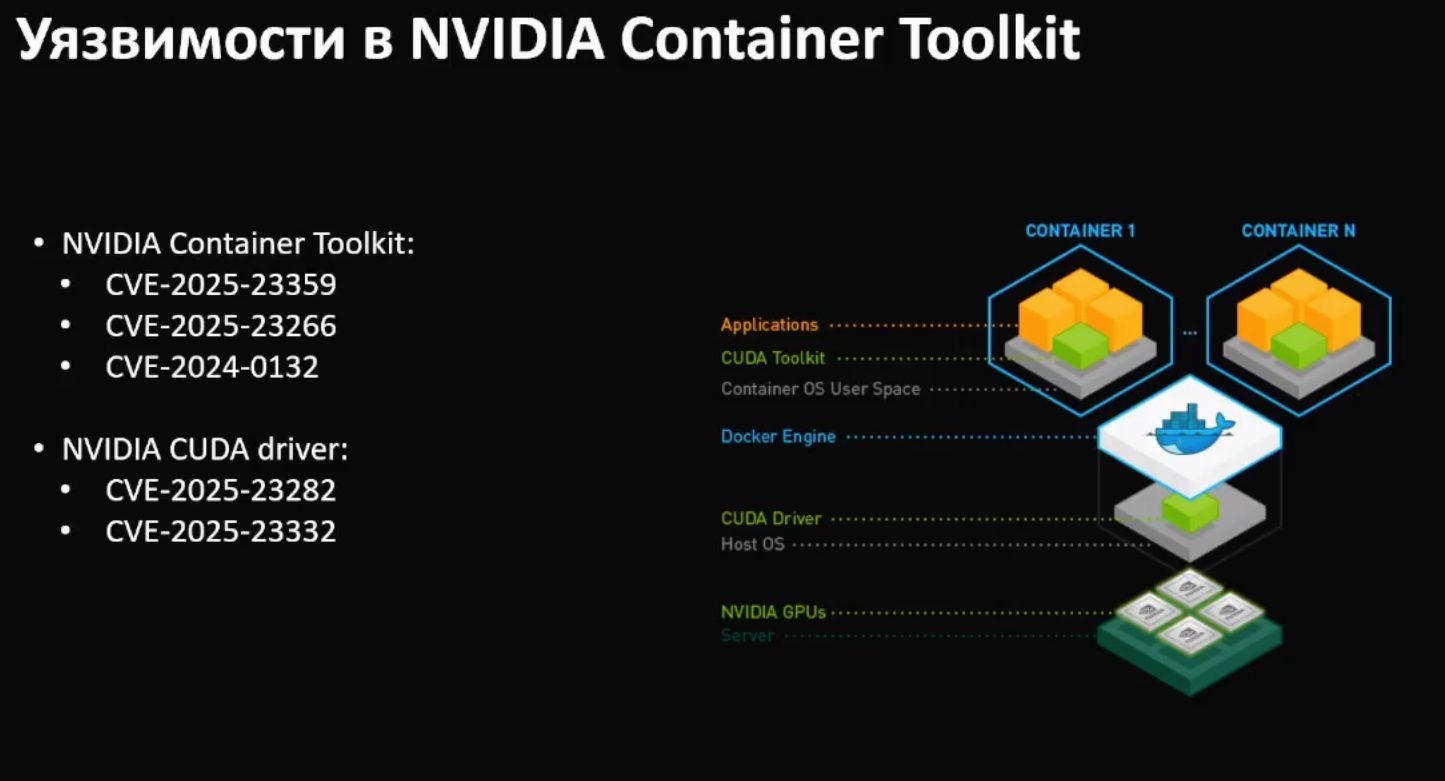
В прошлом году наблюдался значительный рост интереса к анализу AI компонентов. Они активно использовались в баг баунти программах, CTF и PoC соревнованиях, а вознаграждения за найденные уязвимости были высокими. Исследователи из разных компаний выявили множество уязвимостей в NVIDIA Container Toolkit, который является де-факто стандартом для работы с NVIDIA.
Были обнаружены критические уязвимости, отличающиеся простотой эксплуатации. Специально сформированный Dockerfile при запуске образа позволяет осуществить побег из контейнера. Подобный сценарий реализуем специалистом, формирующим образ, поскольку он загружает собственное программное обеспечение, драйверы NVIDIA, данные и датасеты для AI ML задач. Таким образом, он полностью контролирует образ в рамках модели нарушителя.
Эксплуатация осуществляется через логические уязвимости, проблемы с симлинками и состояния гонки. В связи с этим необходима тщательная проверка, иначе побег из контейнера становится тривиальной задачей.
Проблема обновления обусловлена высокой загрузкой AI ML кластеров, которые эксплуатируются с максимальной интенсивностью без простоев. Между тем для обновления требуется остановка работы. Компании часто не обладают информацией об этой проблеме или избегают простоев. В 100% проверенных инфраструктур с NVIDIA Container Toolkit была зафиксирована уязвимость в рамках модели нарушителя, доступ удавалось получить в течение десятков минут.
Необходимо предусмотреть время на обновление. Процессы, связанные с AI ML кластерами, требуют значительного времени. В ряде проектов доступ к ним удавалось удерживать достаточно долго, а исправление уязвимостей – процесс также довольно продолжительный. Инфраструктурные изменения, связанные с оборудованием, требуют дополнительных временных затрат.
Сетевая безопасность
 В кластере наблюдается значительный east-west трафик между подами, связанный с инференсами, процессингом и синхронизацией моделей. Передаются большие объемы данных, при этом кластеры обучения и инференса часто разделены.
В кластере наблюдается значительный east-west трафик между подами, связанный с инференсами, процессингом и синхронизацией моделей. Передаются большие объемы данных, при этом кластеры обучения и инференса часто разделены.
Необходим мониторинг сетевой активности с анализом, сегментацией и выявлением нелегитимных действий. В отличие от стандартных кластеров с обычной нагрузкой, здесь критично влияние средств защиты, работающих в разрыв. Открытые и коммерческие решения, такие как DPI-движок NeuVector, внедряются в трафик для распаковки и анализа, что приводит к заметному замедлению работы сети и негативно сказывается на производительности окружения.
Единственным решением, сочетающим удобство, производительность и отсутствие влияния на потоки данных, остается встроенный межсетевой экран Kubernetes на базе ресурса NetworkPolicy. Однако нативные политики ограничены уровнями L3 и L4. Для фильтрации по URL или API этого недостаточно, требуются кастомные политики уровня L7 от Calico или Cilium.
Защита рантайма
Рантайм представляет собой код и процессы внутри контейнеров. Код изначально содержит уязвимости.
Shadow уязвимости возникают, когда известная проблема не получает CVE, так как разработчик объявляет ее не уязвимостью, а функциональностью. Примером служит десериализация Python объектов, широко применяемая в AI ML стеке. С помощью специально сформированного десериализованного объекта можно добиться произвольного выполнения кода. В этой сфере распространена шаблонизация, а атаки через pickle эффективно реализуются без регистрации CVE.
При формировании SBOM через компонентный анализ такие возможности не будут обнаружены. AI ML стеки повсеместно подвержены этой проблеме. Примеры включают TensorFlow, PyTorch, Ray и другие библиотеки, где подобная функциональность заложена архитектурно. Форматы данных, например, с расширением h5, позволяют выполнить произвольный код, хотя для непосвященных они выглядят безобидно. Веса нейросетей следует рассматривать не как статические массивы данных, а как потенциальный вектор для выполнения кода.
Использование нейросетей и запуск датасетов без надлежащей валидации фактически приводят к RCE на входе, при этом CVE не присваиваются ввиду архитектурного подхода.
Необходимо тщательно контролировать все компоненты, работающие в контейнерах, в том числе запущенные процессы, их права, порождаемые подпроцессы, а также файловую и сетевую активность.
Для долгоживущих ML задач, выполняющих вычисления или обучение, сетевая активность не является нормой. Ключевое значение приобретает профилирование для определения штатного поведения нагрузок. Без этого применение «черных списков» малоэффективно.
Существует проблема больших объемов данных и сетевого трафика, а также быстро порождаемых задач. Высокая интенсивность операций, например, сотни тысяч файловых операций в секунду, требует от средств безопасности значительных вычислительных ресурсов. Если мониторинг выполняется на конечном узле, нагрузка становится критической. Даже одно правило требует сотен тысяч сравнений в секунду, а при наличии десятков правил количество операций достигает миллионов, что создает избыточную нагрузку на сенсор, кэш и другие ресурсы.
Подобная архитектура, ориентированная на обработку на сенсоре, характерна для большинства open source решений, в частности, Falco, Tracee, Tetragon, а также для многих коммерческих продуктов.
Аутентификация и права доступа
Аутентификация ML приложений – распространенная проблема, хотя напрямую не связана с Kubernetes. В ходе работ в разных компаниях встречается множество API и веб-интерфейсов. Идентификация настраивается выборочно, а при подготовке отдельной командой ML используются разнородные технологии с нестандартными портами.
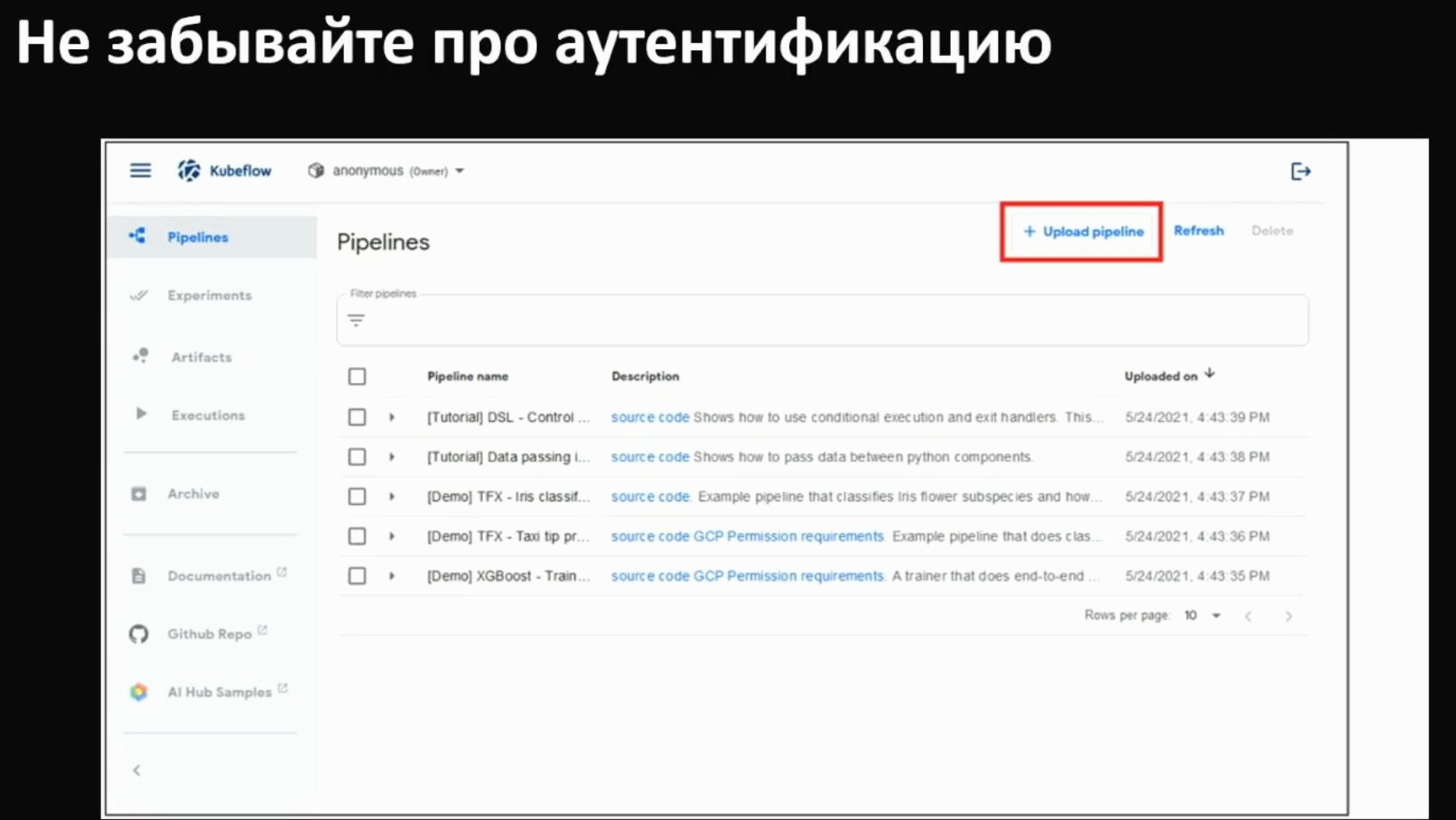
Показателен пример Kubeflow. Несколько лет назад злоумышленники создали сканер Интернета для поиска экземпляров без аутентификации. Через такой интерфейс можно запустить произвольную нагрузку указав образ. Атакующим это давало преимущество в виде доступа к кластерам с видеокартами для майнинга.
Ситуация сохраняется. Многие проекты используют собственные обертки на основе готовых решений для TensorFlow и аналогичных инструментов. Аутентификация критически важна, так как часто позволяет определять запускаемые задачи подобно Kubeflow.
Управление доступом строится на принципе наименьших привилегий. Инженерам предоставляется доступ к нативным и кастомным ресурсам, а также к образам.
В некоторых случаях существовал прямой доступ, позволяющий выполнить kubectl exec (т. е. запустить произвольные команды внутри работающего контейнера) из кода. У более зрелых клиентов функционируют отдельные платформы, исключающие прямые доступы и exec к нагрузке. Data Science инженер через портал выбирает базовый образ, дата-сет и подготовленные инструкции. Запуск выполняется через интерфейс, доступы разграничиваются. Долгоживущие процессы работают автономно, интерактивная работа ведется через Jupyter Notebook. Прямой доступ к контейнеру или коду отсутствует.
Способ предоставления доступа Data Science инженерам определяется внутренними стандартами компании.
Как Luntry учитывает эти аспекты
В качестве решения спикер представил Kubernetes-native платформу Lunrty. В процессинговых центрах раз в секунду порождаются 100 тыс. потоков для обработки одной финансовой транзакции, а в банковских сервисах поддерживается огромное количество подключений мобильных клиентов. Данное решение предназначено для защиты сервисов, которые находятся под постоянной высокой нагрузкой.
Логика детектирования вынесена на бэкенд, следовательно, на воркер-нодах потребление ресурсов не растет в зависимости от количества правил и политик, а нагрузка остается стабильной.
Сетевую безопасность продукт реализует через нативные для Kubernetes механизмы, такие как NetworkPolicy. Это исключает просадки производительности, а проблемы с ним не влияют на работоспособность среды.
Средство адаптируется к любому окружению, будь то популярный open-source оператор или собственное решение заказчика, и контролирует ресурсы на уровне Policy Engine и Kubernetes Audit Log.
За прошлый год в продукт добавили собственные детекторы для эксплойтов и побегов из контейнеров, включая сценарии с NVIDIA GPU. Например, детектор для уязвимости CVE-2024-0132 срабатывает уже на этапе анализа Dockerfile. Подобных проверок нет в open-source и коммерческих решениях. Это позволяет выявлять вредоносные образы на ранних этапах в CI/CD
Выводы
Анализ показывает, что хотя требованиями охвачены все домены защиты, прямое перенесение стандартных подходов, применяемых для обычных (не GPU) кластеров, в данном контексте неэффективно. В большинстве доменов формируется специфика, обусловленная большими объемами данных, особенностями стека и характером сетевой активности. Игнорирование этой специфики приведет к невозможности обеспечить полноценную защиту и, как следствие, к неудовлетворенности результатом со стороны заинтересованных лиц.
Артем Пермяков, Connect


